且将杯酒对星河
介绍
本文将实现使用户环境(即进程)运行的内核功能。在本实验中,你需要:
- 建立起跟踪进程的数据结构
- 创建一个进程
- 载入程序镜像
- 让程序运行
- 处理进程的系统调用
开始
1 | athena% cd ~/6.828/lab |
首先,合并lab2,然后切换至lab3,在lab3中,你需要参考及阅读的源码如下:
| 目录 | 文件 | 功能 | 进度 |
|---|---|---|---|
inc/ |
env.h |
Public definitions for user-mode environments | 完成 |
trap.h |
Public definitions for trap handling | 完成 | |
syscall.h |
Public definitions for system calls from user environments to the kernel | ||
lib.h |
Public definitions for the user-mode support library | ||
kern/ |
env.h |
Kernel-private definitions for user-mode environments | |
env.c |
Kernel code implementing user-mode environments | ||
trap.h |
Kernel-private trap handling definitions | ||
trap.c |
Trap handling code | ||
trapentry.S |
Assembly-language trap handler entry-points | ||
syscall.h |
Kernel-private definitions for system call handling | ||
syscall.c |
System call implementation code | ||
lib/ |
Makefrag |
Makefile fragment to build user-mode library, obj/lib/libjos.a |
|
entry.S |
Assembly-language entry-point for user environments | ||
libmain.c |
User-mode library setup code called from entry.S |
||
syscall.c |
User-mode system call stub functions | ||
console.c |
User-mode implementations of putchar and getchar, providing console I/O |
||
exit.c |
User-mode implementation of exit |
||
panic.c |
User-mode implementation of panic |
||
user/ |
* |
Various test programs to check kernel lab 3 code |
实验需求
本次实验有AB两个部分,你需要分别完成,并至少完成一个挑战实验。
内联汇编
GCC提供了内联汇编功能,参考该网站获得内联汇编讲解
第一部分:进程和异常处理
inc/env.h包含了进程的一些定义,内核使用Env追踪进程,在kern/env.c中,包含如下全局变量:
1 | struct Env *envs = NULL; // All environments,指向一个进程array |
JOS允许的最大活动线程数定义在inc/env.h中,为1<<10即1024个。env_free_list为不活跃的Env链表,在表中添加或删除Env,即可分配或释放进程。
进程状态
我们使用Env结构体对进程进行描述,Env结构体如下:
1 | struct Env { |
结构体成员功能如下:
env_tf:保存进程未执行时的寄存器,即内核或其他进程运行时的寄存器。发生进程切换时,内核将保存该寄存器。
env_link:指向env_free_list中的下一个空闲进程
env_id:使用当前Env的进程的id,当进程被回收后,内核可能会将同一个Env分配给其他进程,但是进程号会发生改变
env_parent_id:父进程id
env_type:进程类型,对于大多数进程,都是用户进程,即ENV_TYPE_USER
env_status:进程状态,有如下几种:
ENV_FREE:不活跃进程,位于env_free_list中
ENV_RUNNABLE:等待执行的进程
ENV_RUNNING:正在执行的进程
ENV_NOT_RUNNABLE:活跃的进程,但是尚未准备运行,例如等待另一个进程通信的进程
ENV_DYING:僵尸进程,将会在下一次陷入内核时被回收
env_pgdir:保存着当前进程页目录的内核虚拟地址
陷帧
我一直没有对这个名词找到一个合适的翻译,姑且顾名思义,称其为“陷帧”,因为进程切换是需要陷入内核的。
陷帧的作用如下,如果把进程的执行比作动画,动画是一帧一帧播放的,相应地,我们的进程也是一帧一帧执行的,我们使用一个结构体对进程关键信息进行描述。这个结构体称为陷帧。在这个帧中,保存有进程执行时的关键寄存器。当我们进行进程或线程切换时,实际就是先将当前进程的陷帧进行保存,然后加载新进程的陷帧
1 | struct Trapframe { |
分配进程array
在上一个lab中,我们在mem_init函数中为pages[]分配了空间,类似地,分配一个env[],用于保存Env结构体,这个比较简单,参考pages分配过程即可,具体代码如下:
1 | ////////////////////////////////////////////////////////////////////// |
现在你的代码应该能够通过check_kern_pgdir()
进程创建及运行
现在编写kern/env.c中的代码,运行一个用户进程。目前我们尚未提供文件系统,因此我们需要进程加载一个写死在内核中的静态二进制镜像作为进程。Lab3中使用了一些手段,将用户程序与内核进行了强绑定,具体实现可以参考参考文献2。现在,请完成如下函数
练习2:在文件env.c中,完成如下代码:
env_init():初始化所有Env结构体对象,然后添加至env_free_list中,调用env_init_percpu,配置分段硬件优先级(0为内核,3为用户)
env_init()
函数原型
该函数实现了envs以及env_free_list的初始化,其原型如下:
1 | // Make sure the environments are in the free list in the same order |
根据注释,我们可以总结该函数如下工作:
- 将
env_id设置为0 - 将
env按与array一致的顺序插入env_free_list中
函数实现
该工作比较简单,实际就是一个链表的插入问题,直接得到代码如下:
1 | env_free_list = envs; |
改进
上面的实现中,链表是正序插入的,代码比较繁琐,可以采用倒插法实现:
1 | void |
env_setup_vm()
函数原型
1 | // Initialize the kernel virtual memory layout for environment e. |
函数功能
从上面的注释中,我们能抽象出该函数具体的工作,即给进程e分配内核虚拟地址空间。首先我们申请了一张页,该页要作为e->env_pgdir的页目录,我们要将这段空间的虚拟地址给了env_pgdir。此外,还需要手动将该页的引用递增一下。
具体实现
1 | static int |
改进
在上面的实现中,我们还需要对env_pgdir指向的页进行初始化,初始化内核部分,因此还需要下面一句
1 | memcpy(e->env_pgdir, kern_pgdir, PGSIZE); |
这一句说明,每个进程都了解内核的页目录。
region_alloc(struct Env e, void va, size_t len)
为进程e分配长度为len的物理内存,然后映射至va
具体实现
1 | static void |
load_icode()
函数原型
1 | // |
函数功能
这个函数将会为一个用户进程设置初始程序的二进制文件、栈以及处理器标志位,该函数只在内核初始化阶段执行。
具体实现
为了实现该函数,我们需要解决如下问题:
- 将ELF格式的二进制文件载入用户进程内存空间
- 将程序的
.bss段置零 - 映射一个内存页给用户的进程栈
函数具体实现如下:
1 | static void |
调试
这个函数算是partA中最难的函数实现,里面有很多细节一开始没注意到,导致调试时卡在了这里,现在总结一下这个函数中遇到的问题。
首先是内存分配的问题,这里有一个小技巧,要先清空大块内存,再对其中的局部进行拷贝,所以需要将上面的两句内存拷贝和设置语句重新排序
1 | // 将下面这两句 |
然后是内存目录管理,上面的代码遗漏了一个非常重要的部分,即内存目录的切换,由于我们是对用户进程的内存空间进行拷贝,所以必须通知CPU,页目录在e->env_pgdir中,否则CPU还是会继续访问内核内存空间,当访问了不可写的内存区域,内核会发送一个信号停止操作,代码修改如下:
1 | // Change |
现在再来理解一下注释中的这段话
Loading the segments is much simpler if you can move data directly into the virtual addresses stored in the ELF binary. So which page directory should be in force during this function?
这段话的意思就是让我们切换页目录。
最后,我们需要记录一下可执行文件的入口,即第一条语句所在的位置,第一条语句地址是ELFHDR->e_entry,进程e中应当有一个字段专门保存执行时的地址。我们知道CPU是根据eip寄存器找到下一条语句执行的位置的,所以我们要将ELFHDR->e_entry保存于新进程e的陷帧中,即
1 | e->env_tf.tf_eip = ELFHDR->e_entry; |
env_create()
函数功能
创建一个新的进程,然后载入进程的可执行文件
具体实现
1 | // This function is ONLY called during kernel initialization, |
env_run()
函数功能
运行进程,同时实现内核态到用户态的转换
具体实现
1 | // |
至此,我们完成了进程管理的几个关键函数,当执行一个进程时,内核会调用load_icode加载并执行hello程序,直到使用系统调用后,通过int在进入内核中。但是这里会出现问题,OS尚未配置硬件实现用户态到内核态的转换。因此会触发保护异常,但是依然无法处理异常,于是又会触发一个保护异常的保护异常(开始套娃)。最终放弃,并产生一个triple fault然后重启系统。
这里我们进行一些调试,以gdb模式启动内核,然后在env_pop_tf处设置断点。这个是进入用户态之前的最后一个函数,在对现场进行了一些保护后,进程跳转至了0x800020这个地址,然后开始执行用户进程。查看obj/user/hello.asm获得hello中调用的系统调用sys_cputs()中int的地址(说明系统调用是中断触发的)。找到int $0x30所在地址(0x800a9b),设置断点执行,到这一句前应该都没有问题。如果有问题,那一定是你的问题。
中断和异常处理
现在操作系统已经能够实现内核态到用户态的切换,由于中断会进入内核态,所以我们还需要完成用户态到内核态的切换,实现中断和异常。首先先熟悉x86的中断和异常机制
练习3:阅读如下材料,学习中断和异常背后的硬件知识
受保护的控制转移
异常和中断实际上都是受保护的控制转移,即在内核和用户之间的切换。按照英特尔的术语,中断是一种异步控制转移,而异常是同步的。受保护是指:当中断或异常发生后,当前运行的代码只能以指定的方式进入内核。在x86中,保护是由两种机制提供的:
1 中断描述表(IDT):处理器保证进程只能由内核提供的进入点进入内核。x86提供了256个进入点,即256个中断向量(0-255)。中断向量由中断来源决定。CPU根据中断向量,到中断描述表指定的位置寻找中断描述符,并加载如下内容:
- 将中断服务函数入口载入EIP中
- 将服务函数所在的代码段保存在CS寄存器中
2 任务状态段(TSS):在处理中断和异常前,处理器需要一个空间保存旧的状态,例如CS和EIP寄存器中的值,以便后续恢复现场。保存这些状态的空间必须被严格保护,禁止低权限的用户进程访问。因此当发生用户态到内核态的切换时,OS会切换至一个位于内核内存空间的堆栈段,并对关键数据进行保存。TSS即设置了这个堆栈的段选择符和地址。处理器会将SS, ESP, EFLAGS, CS, EIP和一些错误码保存在堆栈中,并从中断描述符中加载CS和EIP,并设置指向新堆栈的ESP和SS。
在JOS中,我们只利用TSS来保存内核堆栈的位置,实际的操作系统中TSS还有许多其他功能。
异常和中断的种类
这一节详见关于中断和异常区别的讲解。本节我们将会处理0-31号中断。下一节我们会处理48号软中断。在Lab4中,我们还会添加一些外部中断,例如定时器中断等。
一个例子
假设处理器正在执行一个用户进程,结果遇到了除零异常,处理器会这样处理:
1 根据TSS中的SS0和ESP0字段,跳转至内核栈字段,在JOS中,SS0和ESP0的值分别为GD_KD和KSTACKTOP
2 将异常参数压入内核栈中,栈顶地址为KSTACKTOP,压完后内核栈如下所示:

3 由于我们在处理除零错误,其中断向量号为0,因此处理器读取IDT的入口0,并设置CS:EIP至中断服务函数的入口地址
4 处理函数将会接管并处理异常,例如退出用户程序等
对于特定型号的x86处理器,除了上面的五个标准字段,还会向栈中压入一个错误码(一般是32位),关于错误码详见IA-32 Developer’s Manual 第五章第13节。有了错误码后,在返回时必须弹出错误码,否则会返回错误的位置执行程序。
中断/异常嵌套
中断可能是在内核或者用户态产生,只有从用户态进入内核态时,才需要进行堆栈的切换,即对用户态堆栈的地址进行保存。如果已经位于内核中,那么内核就不需要进行栈切换,直接保存旧的CS和EIP即可。此外,对于内核产生的中断,我们可以很轻易地进行嵌套处理。因为内核处理自己的中断,可以简单地理解为函数调用。
极端情况下,当中断嵌套过多后,内核栈会爆掉,这种情况下内核只能重启。一个设计良好的内核应该确保这种极端情况永远不发生。
设置IDT
现在,我们开始设置IDT,处理中断向量号为0-31的中断,首先,阅读 inc/trap.handkern/trap.h,这两个文件包含了一些和中断、异常相关的重要定义。其中,kern/trap.h包含着和内核严格私有的代码,而inc/trap.h包含着和内核和用户态相关的代码。
注意,0-31号向量中有一些是保留的,这些不需要处理。我们实现的中断控制流应当如下所示:
1 | // 通过IDT,在trapentry中找到中断服务函数入口,然后跳转至trap中 |
每一个异常或中断都需要有自己的中断服务函数(在trapentry.S中),同时trap_init()将对IDT进行初始化,写入这些服务函数的地址。每个服务函数应当在栈上建立一个struct TrapFrame,然后调用trap()并传入建立的陷帧 (在 trap.c) 。trap将会使用特定的服务函数处理中断和异常。
练习4:编辑trapentry.S和trap.c,实现上述功能。trapentry.S中的 TRAPHANDLER 和TRAPHANDLER_NOEC 宏以及inc/trap.c中的T_*能够帮助你。你需要在trapentry.S中为inc/trap.h中的每一个trap添加一个入口,并提供_alltraps作为TRAPHANDLER的参考。同时,你需要修改trap_init(),初始化idt,令其指向trapentry.S中定义的每一个入口,此处请使用SETGATE宏。
你的_alltraps应当:
- 将对应的值压入栈中,使栈看起来像一个陷帧
- 将
GD_KD载入%ds和%es pushl %esp,向trap()传递一个指向陷帧的指针call trap(trap可以返回吗?)
使用pushal,这个指令符合struct Trapframe的布局,在完成上述内容后,make grade应当能够通过Part A
练习4的要求挺多的,我们将问题一个一个拆解,分而治之。经过拆分后,练习4一共需要完成如下功能:
- 在
trapentry.S中为inc/trap.h中的每一个trap添加一个入口 - 编写
_alltraps函数 - 修改
trap_init(),初始化idt,令其指向trapentry.S中定义的每一个入口
实现顺序
为了解决这个问题,我们考虑如下实现顺序:
- 首先,在
trapentry.S中添加入口,但是不实现 - 修改
trap_init(),初始化idt,令其指向每一个入口
在trapentry.S中为inc/trap.h中的每一个trap添加一个入口
TRAPHANDLER 和TRAPHANDLER_NOEC
我们首先来看一下这两个宏函数,其定义如下:
1 |
|
这两个宏函数能够帮助我们定义中断服务函数入口,例如我们想定义vector0作为中断0的入口,那么只需要写入下面的代码:
1 | TRAPHANDLER_NOEC(vector0, 0) // 中断0 入口为 vector0,向量号为0 |
这个宏会被扩展为:
1 | .globl vector0; |
具体实现
根据上面的两个宏,我们能够写出入口函数的定义如下所示,需要注意的是我们要查询硬件手册,看哪些中断要记录Error Code,哪些不需要。同时,中断向量号已经给出了我们宏定义,具体实现如下:
1 | /* Set up the entries for traps, care about whether |
编写_alltraps函数
函数功能
通过查看xv6 手册中关于alltrap的讲解,可知这个函数完成了如下几件事请:
- 将
%ds、%es、%fs、%gs进行保存 - 然后将
eax、ecx、edx、ebx、oesp、ebp、esi、edi这些寄存器进行保存,这些操作可以用pushal一次性实现 - 将
GD_KD载入%ds和%es pushl %esp,向trap()传递一个指向陷帧的指针call trap(trap可以返回吗?)
具体实现
根据上面总结的功能,我们能够得到_alltraps的实现如下:
1 | .globl _alltraps |
修改trap_init(),初始化idt,令其指向trapentry.S中定义的每一个入口
函数功能
trap_init()函数的功能就是初始化idt,将idt数组中第$i$个值idt[i]设置为trapentry.S定义的入口。这里需要我们了解idt的具体格式,参考x86_idt.pdf (mit.edu)。在mmu.h中定义了struct Gatedesc对中断描述符进行描述,具体即每一位的作用
1 | struct Gatedesc { |
我们使用SETGATE宏函数实现idt到入口的绑定,该函数见本文附录,为了正确调用这个函数,需要依次考虑如下问题:
- 中断服务函数入口的代码段在哪里?在内核的代码段,查看
memlayout.h可知,为GD_KT(0x08) - 是什么类型的,中断?异常?查看中断描述符手册
- 中断服务函数入口的偏移量又是多少 ?即
TRAPHANDLER和TRAPHANDLER_NOEC定义的函数的偏移量
具体实现
具体绑定过程代码如下:
1 | void trap_init(void){ |
结果写完之后一运行,提示这些函数入口都没定义,这个就很难受了,参考xv6的源码,我们还需要在trapentry.S中手动添加*_entry的入口地址,在trapentry.S中设置一个代码段,创建vectors数组,将每一个*_entry对应的地址进行保存:
1 | .data |
在有了vectors数组后,我们还可以采用循环的方式对idt进行初始化,代码如下:
1 | void |
这里我们只针对前19个idt进行初始化,其他的先忽略。
调试与总结
在完成上面的相关代码后,我们现在应该能够运行用户程序,然后对异常进行处理,运行make grade应该能够通过 divzero、softint、 badsegment三个测试,通过part A,然后获得三十分。然而我的代码有问题,需要进行调试。
我们先针对divzero进行调试,查看divzero的输出日志,截取其中的栈帧部分,可以看到如下内容:
1 | TRAP frame at 0xefffffb4 |
可以看到trap一行显示的是 unknown trap。除零应当是除零中断,怎么能是unknown trap呢,说明我们在处理栈帧的时候出现了问题,最有可能的是_alltraps写错了,导致栈布局不对。经过对比,因为我直接参考了xv6的代码,所以多压入了两个寄存器,直接导致栈布局错误,将下面两行删除即可:
# pushl %fs
# pushl %gs
现在运行可以通过divzero,然后此处我又犯了一个小bug,由于我使用循环的方式对前19个中断进行处理,然而上面的代码中我注释掉了两个保留的中断向量入口,这就导致idt和vectors的映射关系错误了,后面的中断都往前移动了一个,所以如果不是采用一一赋值的方式,上面的代码就不能注释掉,并检查对应关系。修改之后即可通过Part A。
问题:回答下面的问题
- 为何每个中断/异常都要有自己独立的服务函数,如果所有的中断/异常都被送入同一个入口,那么上面的什么机制无法实现?
- 是否需要做一些修改,使得
user/softint表现正常?打分脚本期望产生一个通用保护错误(trap 13),但是softint的代码中写了int $14。为何触发了中断向量13?如果内核允许softint的int $14命令触发一个缺页异常,会发生什么?
回答:
- 错误码无法实现,因为有的中断保存错误码,有的不保存,所以必须要不同的入口
- 在这里我们首先要明白什么情况会触发trap 13,通过查阅80386手册9.8.13节可知,所有的不触发其他中断的错误,都被归类为GP,其中第14条说:如果在非内核态(privilege 0)中触发中断,那么就会产生这个异常。所以我们不需要修改,操作系统的处理是正确的。如果引发了一个缺页异常,就是用户态直接调用了中断指令,这样做有悖于其优先级。
第二部分:页错误、断点异常、系统调用
处理页错误
页错误(中断号14:T_PGFLT)是一个非常重要的异常。当处理器触发页错误后,会在CR2中保存触发页错误的指令的地址。 在trap.c 我们提供了 page_fault_handler()处理页错误。
练习5:修改 trap_dispatch() ,向page_fault_handler()发送页错误。现在make grade应该能通过faultread、faultreadkernel、faultwrite以及faultwritekernel。你可以使用make run-x命令令JOS启动后执行对应的用户程序,例如make run-divzero
trap_dispatch()
这个函数的功能是根据不同的中断号,调用具体的服务函数,dispatch的意思是派遣。那么为了解决page fault,我们只需要写下下面的代码:
1 | static void |
现在应该能够通过题目中说的几个函数,再拿到20分
断点异常
断点异常(T_BRKPT=3)允许调试器在代码中插入断点,这个异常一般用于调试器插入断点,通过替换相关语句为一个1 byte的int3软中断指令。在JOS中,我们将针对该指令做一些调整,令其变为一个伪系统调用供用户程序使用。实际上,lib/panic.c中的panic()函数就通过调用int3实现了中断过程。
练习6:修改 trap_dispatch() ,添加断点异常并激活kernel monitor
这个任务比较简单,直接给出代码,先写一个breakpoint的handler函数,然后在trap_dispatch中添加对应的路径即可
1 | void |
这里需要注意的是int3的DPL为3,即SETGATE的最后一个参数是3,否则用户进程无法激活该中断。
挑战任务!:修改 trap_dispatch() ,添加断点异常,使得程序能够从当前位置继续执行(即在由断点异常引发的int3语句执行后)。实现真正的单步调试功能。你需要掌握EFLAGS中每一位的作用。
问题:
- 根据
IDT初始化的过程,breakpoint中断会产生通用保护错误或者断点异常。为什么?你需要如何设置IDT,使得breakpoint产生断点异常? - 你认为这个机制的目的是什么?
回答:
- 我们需要设置breakpoint中断
idt的DPL为3,这样就允许用户进程激活该中断。 - 这个机制一方面可以保护内核,让用户进程不能随意动用中断来进入内核态;另一方面也开放了一些中断,方便用户执行一些特定的功能,例如断点调试等。
系统调用
用户进程通过系统调用向内核请求服务。当用户进程激活系统调用后,处理器会进入内核态,处理器和内核共同合作保存用户进程的状态,随后内核执行系统调用,然后返回用户进程。
在JOS中,我们使用int指令产生处理器中断。我们将int $0x30用作系统调用中断,中断号为T_SYSCALL。设置系统调用中断的idt,使得用户能够触发该中断。
应用会将系统调用号和系统调用参数放置在寄存器中。这样,内核不需要在用户进程的栈或者指令流中读取。系统调用号将被放入%eax中,参数(最多五个)将分别进入 %edx、%ecx、%ebx、%edi和%esi。内核将返回值放入%eax。在lib/syscall.c的syscall()函数中提供了激活系统调用的代码,阅读并理解其中的内容(lib中的syscall是给用户使用的,通过int指令激活系统调用)。
练习7:添加系统调用中断T_SYSCALL的服务函数,编辑kern/trapentry.S和kern/trap.c的trap_init()。修改trap_dispatch(),通过调用kern/syscall.c的syscall(),并根据适当的参数,处理系统调用。将返回值保存在%eax中。最后,修改kern/syscall.c的syscall()。请阅读lib/syscall.c,并弄明白里面的内联汇编语句。通过激活对应的内核函数,处理inc/syscall.h中的所有系统调用。
通过make run-hello运行user/hello,现在应当在控制台打印”hello world”,并触发页错误。同时,make grade应当能通过testbss。
练习7可以分为如下几个部分分别完成:
阅读lib/syscall.c
这个文件中syscall()函数的关键代码是一句内联汇编,关于内联汇编可以参考关于内联汇编的讲解。这句内联汇编如下所示:
1 | asm volatile("int %1\n" // volatile 禁止优化 |
添加系统调用中断的框架
和上面的几个中断类似,这里直接给出代码。首先,在trap.h和trap.c中分别加入下面的代码:
1 | /*在 trap.h 中添加服务函数声明*/ |
然后在trapentry.S中添加入口:
1 | TRAPHANDLER_NOEC(syscall_entry, T_SYSCALL) # vector48: system call |
在trap_init()中设置系统调用idt
1 | SETGATE(idt[T_SYSCALL], 0, GD_KT, syscall_entry_, 3) // 这里因为系统调用号是48,和前面的不相连 |
最后在trap_dispatch()中添加系统调用处理分支
1 | case T_SYSCALL: |
编写系统调用服务函数
系统调用服务函数的主要职责就是获取系统调用参数,并调用syscall函数。
1 | void |
然而上面这个函数有点问题,我们没有保存系统调用的返回值,根据syscall.c中的内联汇编代码,我们需要将返回值存储至eax寄存器中,所以上面的代码需要稍作修改:
1 | tf->tf_regs.reg_eax = syscall(syscallno, arg1, arg2, arg3, arg4, arg5); |
编写syscall()
在kern/syscall.c中,根据系统调用编号,调用对应的系统调用服务函数。这里主要注意一下输入参数和返回值即可,实现如下:
1 | // Dispatches to the correct kernel function, passing the arguments. |
改进:使用Python脚本自动生成trapentry.S
自己手写维护trapentry.S中的中断入口不仅耗时耗力,还很容易出错,因此这里用python写一个脚本,自动生成包含256个中断的中断服务函数入口,以及保存这些入口的vectors数组。基本思路是采用循环语句构造中断服务函数入口函数以及入口函数地址数组。然后再对Makefile进行修改。脚本就不在此处列出了。
Challenge! Implement system calls using the sysenter and sysexit instructions instead of using int 0x30 and iret.
The sysenter/sysexit instructions were designed by Intel to be faster than int/iret. They do this by using registers instead of the stack and by making assumptions about how the segmentation registers are used. The exact details of these instructions can be found in Volume 2B of the Intel reference manuals.
The easiest way to add support for these instructions in JOS is to add a sysenter_handler in kern/trapentry.S that saves enough information about the user environment to return to it, sets up the kernel environment, pushes the arguments to syscall() and calls syscall() directly. Once syscall() returns, set everything up for and execute the sysexit instruction. You will also need to add code to kern/init.c to set up the necessary model specific registers (MSRs). Section 6.1.2 in Volume 2 of the AMD Architecture Programmer’s Manual and the reference on SYSENTER in Volume 2B of the Intel reference manuals give good descriptions of the relevant MSRs. You can find an implementation of wrmsr to add to inc/x86.h for writing to these MSRs here.
Finally, lib/syscall.c must be changed to support making a system call with sysenter. Here is a possible register layout for the sysenter instruction:
1 | eax - syscall number |
GCC’s inline assembler will automatically save registers that you tell it to load values directly into. Don’t forget to either save (push) and restore (pop) other registers that you clobber, or tell the inline assembler that you’re clobbering them. The inline assembler doesn’t support saving %ebp, so you will need to add code to save and restore it yourself. The return address can be put into %esi by using an instruction like leal after_sysenter_label, %%esi.
Note that this only supports 4 arguments, so you will need to leave the old method of doing system calls around to support 5 argument system calls. Furthermore, because this fast path doesn’t update the current environment’s trap frame, it won’t be suitable for some of the system calls we add in later labs.
You may have to revisit your code once we enable asynchronous interrupts in the next lab. Specifically, you’ll need to enable interrupts when returning to the user process, which sysexit doesn’t do for you.
Makefile的编写
在编写了对应的python脚本后,我们希望将其写入Makefile中,使其自动化运行,我们最终生成的目标为kern/vectors.S,依赖文件为kern/vectors.py,因此我们可以在kern/Makefrag下添加这样一段:
1 | kern/vectors.S: kern/vectors.py |
当makefile需要依赖kern/vectors.S时,就会找到kern/vector.S,然后执行python命令行,生成vectors.S。查看makefile,我们发现依赖kern/vectors.S的文件为:
1 | $(OBJDIR)/kern/%.o: kern/%.S $(OBJDIR)/.vars.KERN_CFLAGS |
我们需要将第一行修改为:
1 | $(OBJDIR)/kern/%.o: kern/%.S kern/vectors.S $(OBJDIR)/.vars.KERN_CFLAGS |
声明对于kern/vectors.S的依赖关系。这里还有一个疑问,我本来想直接写:
1 | kern/%.S: kern/vectors.py |
即不显式声明对某个文件的依赖,而是用通配符进行处理,但是并不行。这个问题目前暂未解决,先这样吧。
用户模式起步
一个用户程序在lib/entry.S的顶部启动。经过一些配置,这个代码调用位于lib/libmain.c的libmain()。修改libmain(),初始化全局指针thisenv,指向envs[]中当前进程的struct Env 。提示:参考inc/env.h并使用sys_getenvid。
libmain()随后调用umain,这个函数定义在具体的用户程序中。在hello程序中为user/hello.c。注意到打印了”hello, world“后,umain()试图访问thisenv->env_id。而该指针还未初始化好,所以出现了错误。现在我们初始化了thisenv,因此不会出错。如果依然有错误,那么UENVS这个空间可能被设置为了用户不可读。
练习8:在用户库中添加所需的代码,支持用户程序运行。你应当看到user/hello打印hello, world以及i am environment 00001000,然后尝试调用sys_env_destroy()退出(参考lib/libmain.c和lib/exit.c)。由于当前内核仅支持一个用户程序,因此内核会报告销毁了唯一的进程,并进入了内核监视器。现在,make grade应当能够通过hello测试。
练习8要求我们初始化全局指针thisenv并指向envs中的当前进程,我们需要做两件事情:
- 找到当前进程
- 将当前进程对应的地址赋值给
thisenv
第一个任务是靠sys_getenvid()和ENVX实现的,查阅inc/env.h,我们可以知道如何找到进程id,并根据id找到进程在envs数组中的位置。
1 | // The environment index ENVX(eid) equals the environment's index in the |
解决了第一个问题,第二个就很简单了,我们只需要修改libmain.c,加一句话即可。
1 | void |
页错误与内存保护
操作系统依赖于硬件实施内存保护。内核会通知硬件,哪些虚拟内存是有效的,哪些不是。当一个程序尝试访问无效内存或者无权限内存,处理器会在触发错误的指令处停止该语句,并带着相关信息进入内核。如果错误是可修复的,内核修复错误并继续执行程序;否则程序无法继续执行。
As an example of a fixable fault, consider an automatically extended stack. In many systems the kernel initially allocates a single stack page, and then if a program faults accessing pages further down the stack, the kernel will allocate those pages automatically and let the program continue. By doing this, the kernel only allocates as much stack memory as the program needs, but the program can work under the illusion that it has an arbitrarily large stack.
System calls present an interesting problem for memory protection. Most system call interfaces let user programs pass pointers to the kernel. These pointers point at user buffers to be read or written. The kernel then dereferences these pointers while carrying out the system call. There are two problems with this:
- 内核页错误更严重. If the kernel page-faults while manipulating its own data structures, that’s a kernel bug, and the fault handler should panic the kernel (and hence the whole system). But when the kernel is dereferencing pointers given to it by the user program, it needs a way to remember that any page faults these dereferences cause are actually on behalf of the user program.
- The kernel typically has more memory permissions than the user program. The user program might pass a pointer to a system call that points to memory that the kernel can read or write but that the program cannot. The kernel must be careful not to be tricked into dereferencing such a pointer, since that might reveal private information or destroy the integrity of the kernel.
For both of these reasons the kernel must be extremely careful when handling pointers presented by user programs.
You will now solve these two problems with a single mechanism that scrutinizes all pointers passed from userspace into the kernel. When a program passes the kernel a pointer, the kernel will check that the address is in the user part of the address space, and that the page table would allow the memory operation.
Thus, the kernel will never suffer a page fault due to dereferencing a user-supplied pointer. If the kernel does page fault, it should panic and terminate.
Exercise 9.
Change
kern/trap.cto panic if a page fault happens in kernel mode. Hint: to determine whether a fault happened in user mode or in kernel mode, check the low bits of thetf_cs.Read
user_mem_assertinkern/pmap.cand implementuser_mem_checkin that same file.Change
kern/syscall.cto sanity (理智) check arguments to system calls.Boot your kernel, running
user/buggyhello. The environment should be destroyed, and the kernel should not panic. You should see:
1 | [00001000] user_mem_check assertion failure for va 00000001 |
- Finally, change
debuginfo_eipinkern/kdebug.cto calluser_mem_checkonusd,stabs, andstabstr. If you now runuser/breakpoint, you should be able to run backtrace from the kernel monitor and see the backtrace traverse intolib/libmain.cbefore the kernel panics with a page fault. What causes this page fault? You don’t need to fix it, but you should understand why it happens.
练习9一共给了5个任务,我们依次完成:
修改 kern/trap.c,当内核发生页错误时,panic
这里提示我们使用 tf_cs的低位对内核和用户模式进行判断,如果页错误在内核,就将内核中止。这段代码比较简单,在page_fault_handler中添加下面的代码即可:
1 | void |
实现user_mem_check
函数功能
Check that an environment is allowed to access the range of memory [va, va+len) with permissions perm | PTE_P. Normally perm will contain PTE_U at least, but this is not required. va and len need not be page-aligned; you must test every page that contains any of that range. You will test either len/PGSIZE, len/PGSIZE + 1, or len/PGSIZE + 2 pages.
函数原型
1 | int |
函数实现
为了对[va, va+len)进行检查,我们需要完成以下工作:
- 进行内存对齐,找到包含
[va, va+len)的最小对齐内存 - 依次遍历,判断内存是否合法,如果不合法,记录非法内存所在地址
- 内存是否在用户区域内?(
start < ULIM) - pte是否非空?
- pte是否符合perm的要求?(
pte & perm == perm)
- 内存是否在用户区域内?(
1 | int |
修改 kern/syscall.c,检查syscall的调用参数
由于sys_cputs系统调用要对内存进行写操作,因此我们要检查内存是否有效,在/kern/syscall.c的sys_cputs函数中加入进行检查即可。
1 | user_mem_assert(curenv, (void*)s, len, PTE_P|PTE_U); |
运行并查看结果
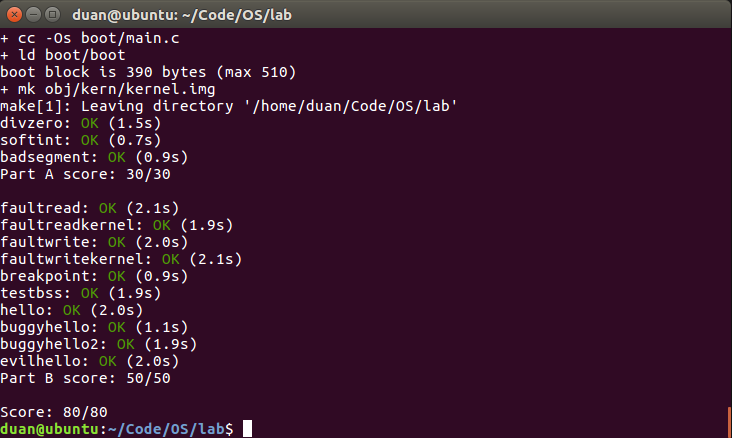
现在你的程序应当能够通过所有的测试,并获得相应的分数。至此,Lab3已经全部完成。
附录
其他几个重要但是不需要我们完成的函数
env_pop_tf(struct Trapframe *tf)
1 | // Restores the register values in the Trapframe with the 'iret' instruction. |
这个函数将一个陷帧弹出,将其中的值恢复给寄存器,即恢复到tf描述的状态。
SETGATE
1 | // Set up a normal interrupt/trap gate descriptor. |
这个函数需要注意的是其中的sel段,这个段设置了中断/陷入handler的代码段,同时,off设置了代码段偏移量