Abstract
Some reading notes about state-space, and feedback and estimators in state space method basically from chapter 8 of Linear system theory and design 1.
State-space
What is a state-space model?
A state-space model, according to reference 22, is a model uses state variables to describe a system by a set of first-order differential or difference equations, rather than by one or more nth-order differential or difference equations. In state-space models, we reconstruct state variables from input-output data rather than measure them directly.
Here’s the mathematical form and block diagram of SS model.
˙x(t)=Ax(t)+Bu(t)+˜Kw(t)y(t)=Cx(t)+Du(t)+w(t)x(0)=x0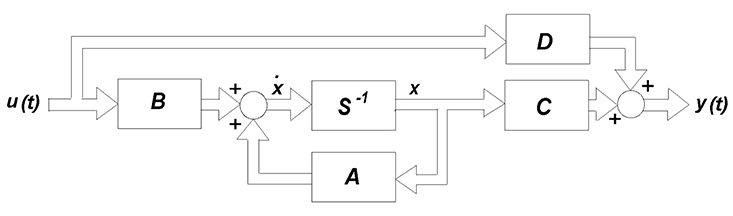
Why we need state-space model
- Can be used for Linear and nonlinear systems.
- For both SISO and MIMO systems.
- First order ODE’s means perfect for analysis
- working in time domain
State-space and transfer functions: conversion
SS to TF
˙x(t)=Ax(t)+Bu(t)y(t)=Cx(t)+Du(t)x(0)=0- Laplace transfer
- Shift Item
In Matlab (God I really like Matlab)
1 | [n,d]=ss2tf(A,B,C,D) |
TF to SS
H(s)=Y(s)U(s)=b0sn+a1sn−1+⋯+an−1s+an- Shift Item and create differential equation
- Choose state variables
- Write as ss form
State Feedback
What is state feedback
Consider a simple open loop SISO ss euqation:
˙x(t)=Ax(t)+bu(t)y(t)=Cx(t)We want use u(t) to change system dynamics, so we introduce linear state feedback with gain k:
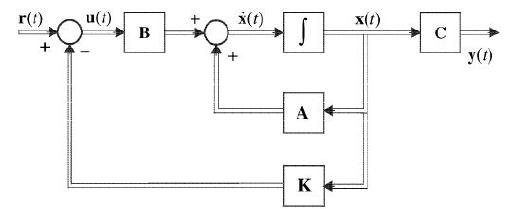
Now the input u is given by u(t)=r(t)−kx(t) and our ss equation becomes:
˙x(t)=(A−bk)x(t)+bu(t)y(t)=Cx(t)Why we need state feedback
From the equations above we replace A with A-bk, we know that A’s eigenvalues give the open-loop system poles, by selecting proper K, we can place the eigenvalues in any positions we what.
- Theorem 1
If n-dimensional ss equation is controllable, the eigenvalues of A-bk can be arbitrarily assigned.
How do we design a proper state feedback
Method 1: According to desired pole placement
To apply pole placement method, first we need to clear how the pole influence the system, please refer to another article:
In Matlab, we give system parameters and desired eigenvalues, the place function will give out the feedback gains. (We choose desired eigenvalues through system performance)
1 | a=[0 1 0 0; 0 0 -1 0; 0 0 0 1;0 0 5 0] |
Method 2: Solving Lyapunov Equation
Same question as above, we want a proper k.
- First, we need a matrix F according to eigenvalues
- Next we select an 1×n vector ˉk makes (F,ˉk) observable
- Then we solve the unique T in Lyapunov equation AT-TF=bˉk
- Finally we compute feedback gain k=ˉkT−1
Matlab codes
1 | a=[0 1 0 0; 0 0 -1 0; 0 0 0 1;0 0 5 0]; |
Method 3: LQR Method
The LQR method is an optimal control method which goal is to find the controller that minimizes a quadratic cost function subject to the linear system dynamics. It’s assumed that
- There is no noise
- The full system is observerable
The mathematical form of LQR is:
minThe optimal controller for the LQR problem is a linear feedback controller with a form of
State Estimator
What is a state estimator
A state estimator or observer is a device generates an estimate of the state. We hope that the output of the estimator is just the same as the behavior of the plant.
Open loop state estimator
Basic structure
First let’s take a look at the open loop state estimator:
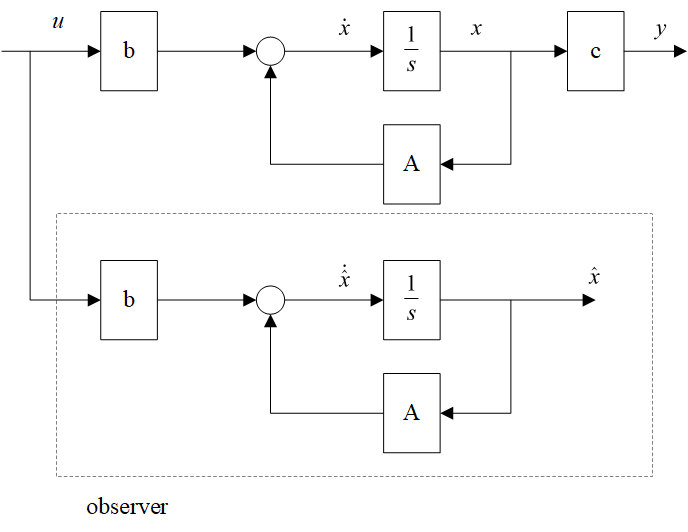
If we know \textbf A and \textbf b, we can duplicate the system as:
The estimation error is \tilde{x}(k)=A^{k}(x(0)-\hat{x}(0)), this is not ideal because:
- The dynamics of the estimation error are fixed by the eigenvalues of A and cannot be modified
- The estimation error vanishes asymptotically if and only if A is asymptotically stable2
Disadvantages:
- initial state must be computed and set each time we use estimator
- There will be a difference between x(t) and \hat x(t)
Close loop state estimator (Luenberger observer)
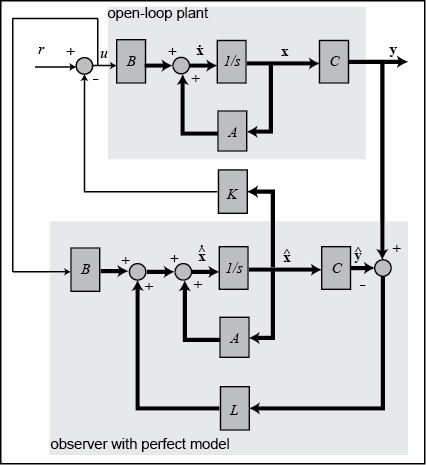
We modify the estimator in which the output y(t)=c{\textbf x}(t) is compared with c\hat{\textbf x}(t), the difference is used as a correlation term. If difference is zero, nothing to do. If the difference is nonzero and gain \textbf l is proper designed, the difference will drive the estimated state to actual state.
Let’s define \textbf e(t) is the evaluated error of state estimation
This is a first order difference function, by choosing a proper L, we can stabilize (\textbf A-\textbf l\textbf c), the solution is an exponential function, thus the state error tends to zero with an exponential form, thus the estimation is unbiased.
From equation \eqref{etxtxht} we can also notice that it doesn’t contain any control quantity, thus it is uncontrollable. However, as long as the system is stable, the estimation error tends to zero if the roots of the characteristic equation \det(s\textbf I-\textbf A+\textbf l\textbf c) fall into the left half plane.
Observer design
1 | x=[-1;1]; % initial state |
Why we need a state estimator
Ideally, the state variables are all available for feedback. In practice, some variables are not accessible. So we introduce observers to the system, for example, in self-driving, we have GPS, IMU, et al. as observers.
How to design a state estimator
The equation \dot{ \textbf{e}}(t)=(\textbf A-\textbf l\textbf c)\textbf e(t) governs the estimation error. If all eigenvalues of (\textbf A-\textbf l\textbf c) can be arbitrarily assigned, we can control the rate for \textbf e(t) to approach zero, so the feedback gain of \textbf l help us to reduce the difference between actual state and observed state. Since we want the dynamics of the observer to be much faster than the system itself, we need to place the poles at least five times farther to the left than the dominant poles of the system.
1 | p=[-1.5+0.5j -1.5-0.5j -1+j -1-j] |
Feedback from estimated states
Now let’s combine the feedback with state estimator, our state variables are not available for feedback, so we design a state estimator to get the observed variables.
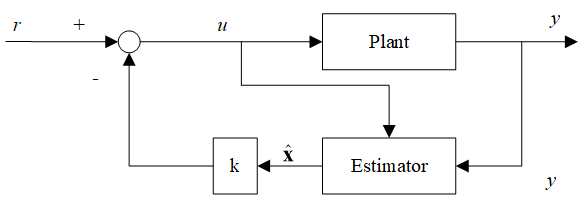
It can be proved that the feedback and estimator are independent and can be carried out independently. This is called the separation property.
Application: State feedback control of a inverted pendulum system
This section is mainly based on a short tutorial from reference 3.
Problem setting
Suppose we have a Pendulum-Cart system to be controlled shown below
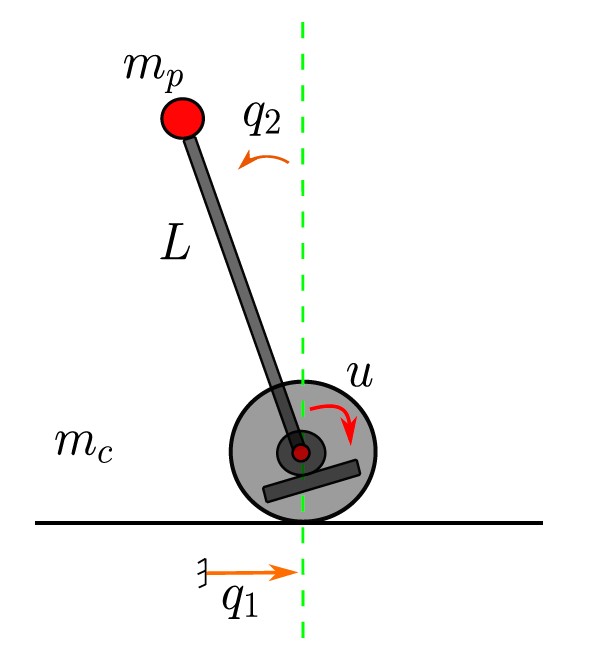
The overall objective will be broken down into the following tasks:
- Linear dynamic system modeling
- System analysis
- Controller designing in SS
- State observer designing and investigating in close loop
- Discretization
Linear dynamic system modeling
We shall not focus too much on the modeling process, here we give out the linear model of inverted pendulum directly:
Let q_1 (position) and q2 (angular) be the system output, \textbf A and \textbf b is:
where: m_c = 1.5,m_p=0.5,g=9.82,L=1,d_1=d_2=0.01.
1 | clc; |
And the plant in simulink is:
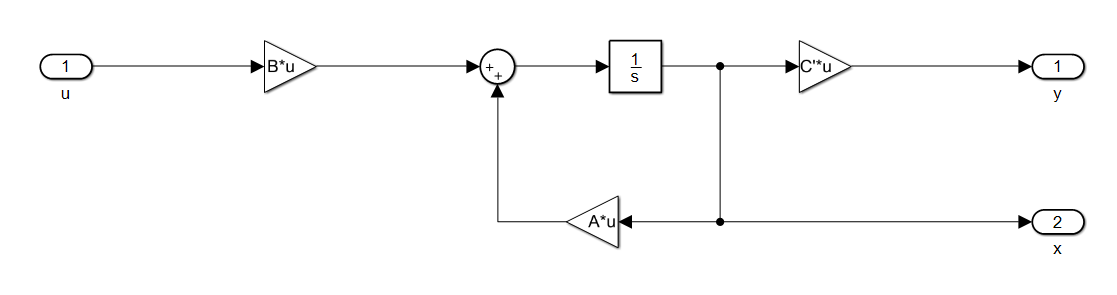
System analysis
Given a zero input, the output of the system shows that it’s not stable:
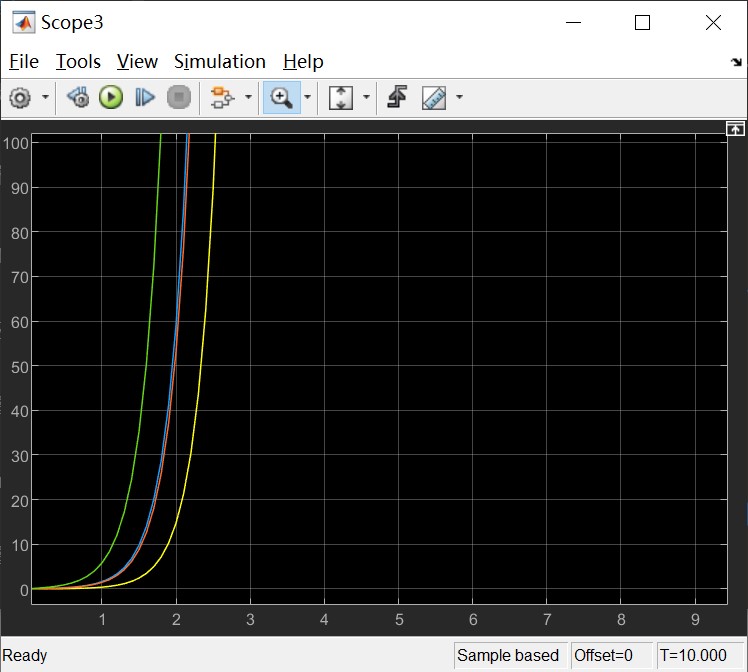
You can also refer to the eigenvalues, the root locus to see the stability of the system.
1 | %% System stability |
Controller designing in SS
First we give out the desire pole we want our system to be set (according to the performance of the system). Based on the desire pole, we can calculate the feedback gain \textbf K (Click here to review state feedback).
1 | %% Controller |
Or we can apply the LQR method to get the gain (Click here to review LQR methood).:
1 | Q = eye(4); |
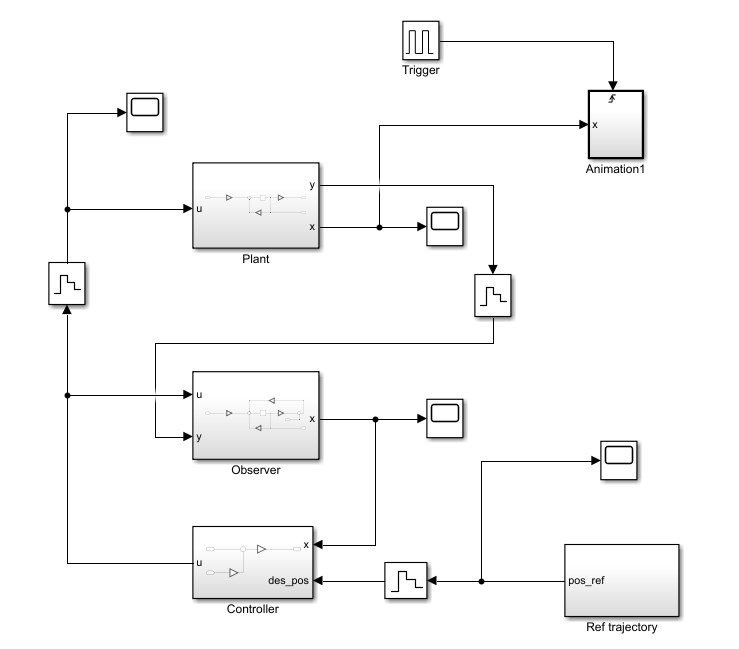
The controller and it’s inner structure is shown below
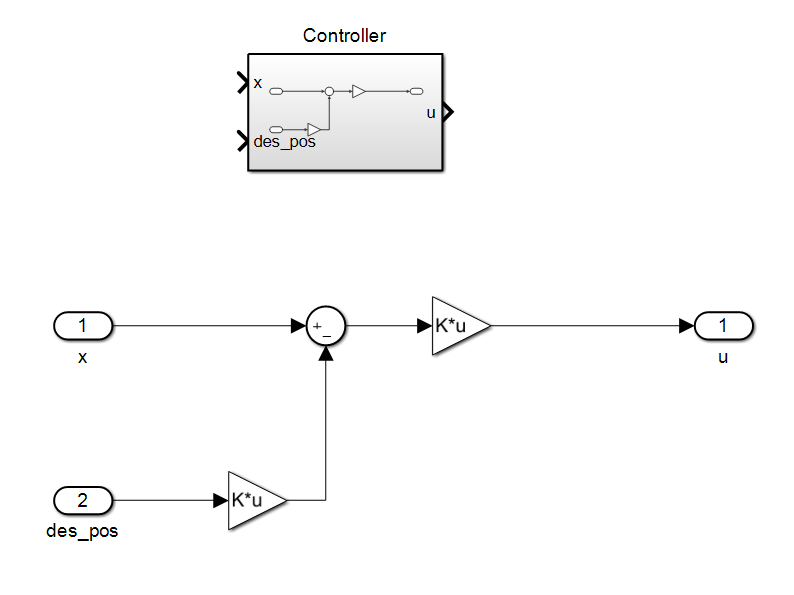
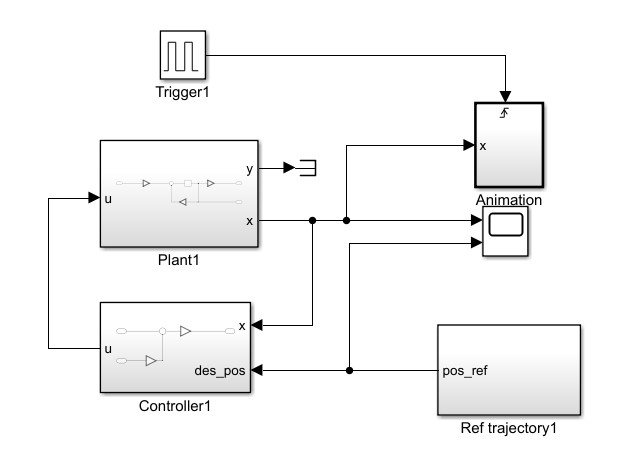
By adding the controller to the system, now we can apply a control behavior to the plant. Given a reference trajectory pulse, we can check the out put of the system. The control system, input and output trajectories and the simulation animation is shown below.
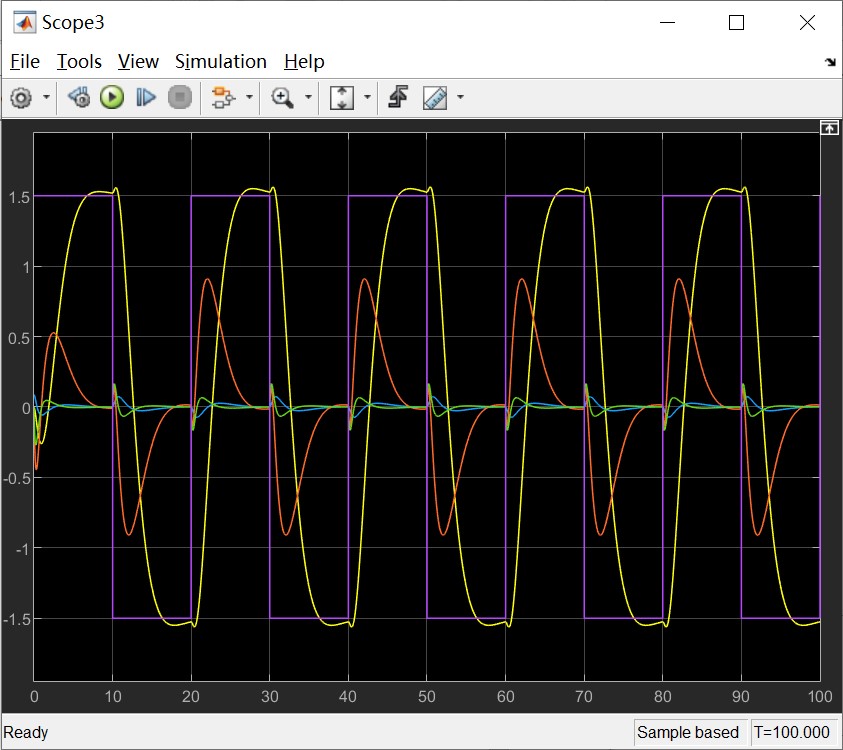
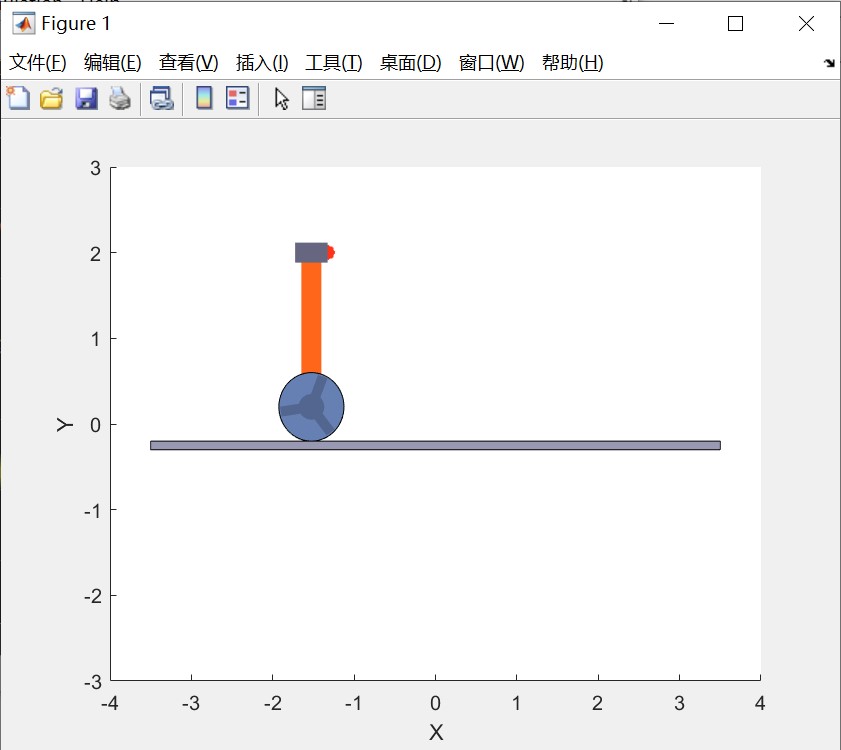
State observer designing and investigating in close loop
So far so good, now let’s further introduce the observer to the system, Click here to review the design process of a state estimator.
1 | L = acker(A',C,des_pole*10); |
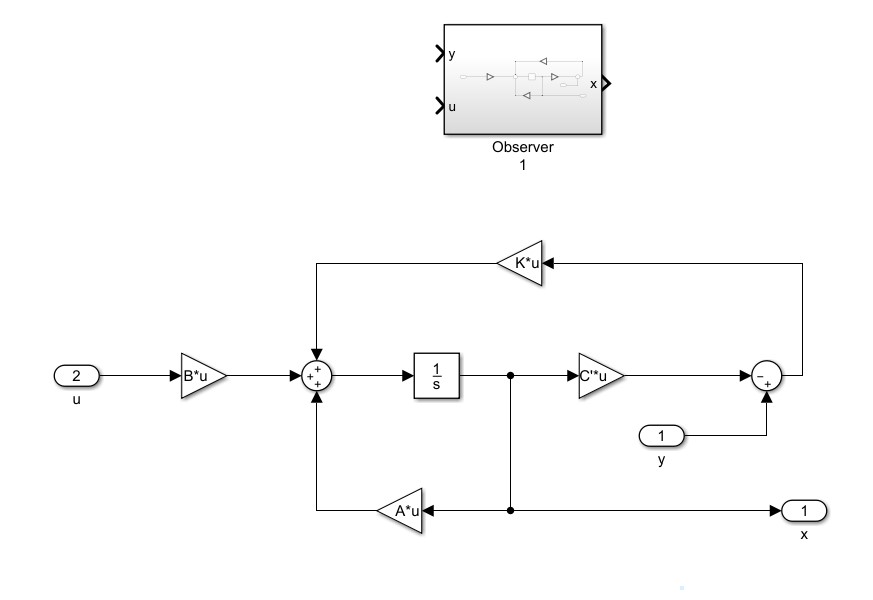
The observer and it’s inner structure is shown below
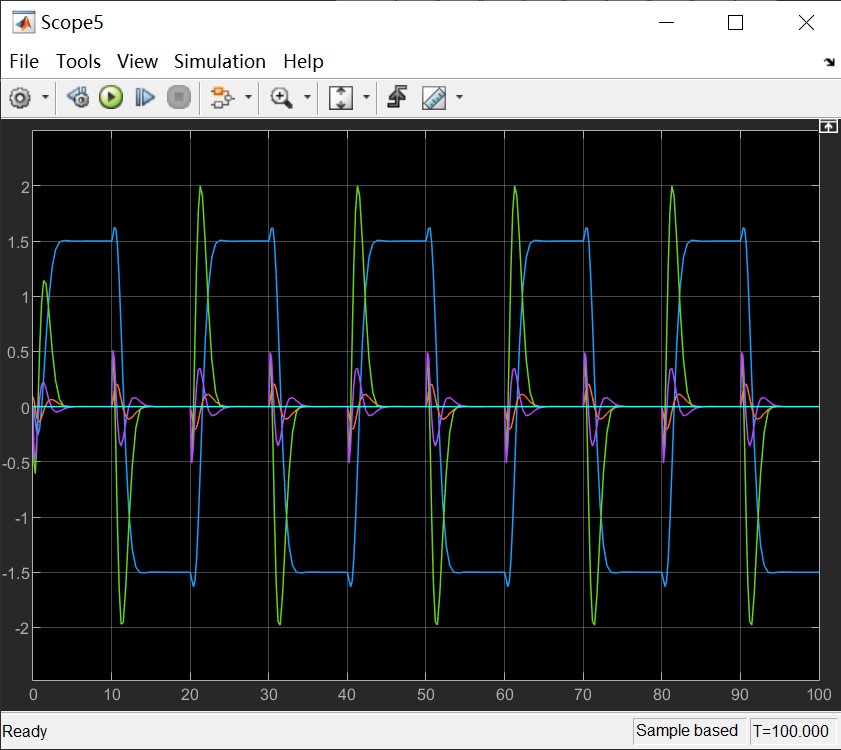
And the output of the observer is quite like the original plant.
Discretization
The final step is to discrete the controller and observer. First we discrete the controller, then the observer.
1 | % discrete |
Then replace the parameters in the system with discrete ones and add zero order holder, change integrator to unit delay model, we get our discrete control system.