Two possibilities exist: either we are alone in the Universe or we are not. Both are equally terrifying.
本文为Udacity Introduction to Operation System 课程9总结
线程描述符
概述
我们知道线程可以分为内核和用户空间的线程。对于支持多线程的操作系统来说,它起着线程抽象、调度以及同步等功能。而对于用户态的线程,需要有特定的库执行上述任务。在本节中,我们来看一看为了支持线程的工作,我们需要哪些数据对其进行描述。
注:在讨论线程描述之前,我们先要了解linux是如何支持线程的,实际上,linux下是没有线程的概念的,虽然有着线程库,但是在内核中并没有真正的对线程的支持,而是使用进程实现线程的功能。进程是进行调度的最小单位,而线程是一个与其他进程共享某些资源的进程,每一个线程拥有一个唯一的task_struct进行描述。
单CPU多进程
在只有一个CPU的情况下,用户态线程和内核线程可以是一对一、多对一或多对多的映射,此时我们的用户层面的线程(User-Level Thread, ULT)需要有如下的信息:
- UL thread ID
- UL thread 寄存器
- 线程栈
- …
而内核层面的线程(Kernel-Level Thread, KLT)包含如下信息:
- 栈指针
- 寄存器指针
进程描述符则包含虚拟内存的映射。当我们有多个进程在运行时,此时ULT、KLT和PCB会构成一组数据。
多CPU多进程
在这种情况下,我们还需要一个数据结构描述CPU,通过一个指向当前CPU上运行的线程的指针,我们可以在CPU、KLT、PCB和ULT之间建立关联。
PCB改进
单个PCB的缺点
在上文中我们强调了Linux没有线程的概念,每一个线程实际上都是一个轻量化的进程,那么自然而然的我们会考虑到用PCB来描述线程,但是这引出了一个问题:如果我们仅仅只用一个PCB描述线程,那么这个数据结构会有下面的问题:
- 这个数据结构会很大,包含了许多连续的数据(规模大)
- 每个线程的PCB应当是私有的(开销大)
- 线程切换时需要保护和恢复现场(性能问题)
- 每一次更新状态需要发生许多改变(灵活性不足)
将PCB拆分为多个数据结构
针对单一PCB的缺点,我们将PCB拆分为多个数据结构,这样有如下好处:
- 每个数据结构规模更小(规模小)
- 更容易分享(开销小)
- 线程切换时所需要保护的数据更少(性能好)
- 只需要改变一部分状态(灵活)
Linux下内核线程结构
在linux内核中,其线程数据结构为kthread_worker,定义如下:
1 | struct kthread_worker { |
而用于描述具体任务的是task_struct结构。
SunOS 下的线程描述设计*1
SunOs中的线程和pthread库中的设计比较类似,当创建一个线程后,会返回一个线程ID(tid),这个index指向一个指针表,而这个指针表指向每一个线程具体的数据结构。这个设计结构如下:
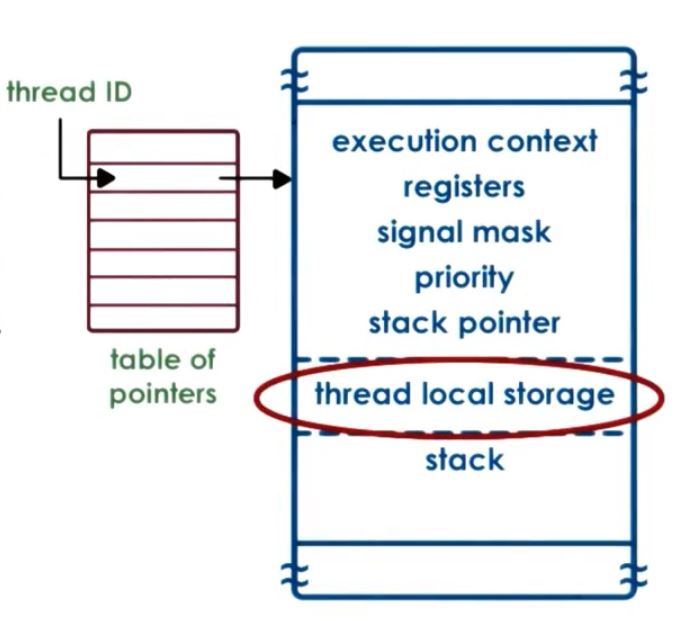
其中,thread local storage保存了线程函数中在编译期间就获知的局部变量。而stack的空间可能由库或用户决定。通过数据结构的大小作为偏移量,即可寻找到相邻的thread,这里的一个问题是stack的增长可能是很危险的,如果栈过长,可能导致下一个线程中的数据被覆盖,引起莫名其妙的问题。在文章中,定义了一个red zone来解决这个问题,一旦栈增长到了红色区域内,就会引发一个错误。