计算机社会学基本公理:第一,内存是进程的第一需要;第二,进程不断增长和扩张,但计算机中的内存总量保持不变。
介绍
内存管理的组成
内存管理可以分为物理内存分配和虚拟内存映射。
内核的物理内存分配器
在内存管理中,我们需要为内核提供物理内存分配器,使内核能够分配和释放内存。分配的单元为页,大小一般为4KB。为了实现分配器,我们需要维护一个数据结构记录哪些内存是已经被分配的,哪些是空闲的,多少个进程在使用已经分配的内存。同时,我们还需要一套用于分配和释放的调度策略。
虚拟内存机制
为了将内核和用户软件的虚拟内存地址映射到实际物理地址,我们需要一个虚拟内存映射机制。当指令使用内存时,x86的内存管理单元(MMU)通过一个页表完成映射过程。为了实现JOS,我们需要去调整相应的页表。
开始
首先创建一个分支lab2,然后将我们在lab1中写的代码合并到lab2中,这一部分请参考lab2中的提示,不再赘述。需要注意的是可能会需要手动处理一些合并过程中的冲突。在本次实验中我们需要关注的新文件如下:
1 | inc/memlayout.h |
memlayout.h描述了虚拟地址空间的布局,你需要通过修改pmap.h实现。memlayout.h和pmap.h定义了PageInfo结构体,根据这个结构体可以查看内存的alloc/free情况。kclock用于操作PC的电池时钟以及RAM,RAM中保存了物理地址的容量及其他相关信息。pmap.c通过读取RAM来确定有多少物理内存可用。
这里重点注意memlayout.h和pmap.h,并复习一下inc/mmu.h
第一部分:物理页管理
操作系统必须跟踪物理内存的使用情况,包括哪些内存被分配了,哪些是空闲的。JOS使用页粒度对内存管理,从而可以使用MMU对已经分配的内存进行保护和映射。
在这一部分,我们需要实现一个物理页分配器,它使用一个链表连接的PageInfo对象对空闲页进行跟踪,每一个PageInfo代表一个物理页。在此基础上,我们会实现一个页表管理器分配物理内存,从而保存页表。(与xv6不同,xv6直接将PageInfo保存在指向的空闲页中)
练习1:一个物理页分配器
在kern/pmap.c中,你需要按顺序实现下列函数:
1 | boot_alloc() |
check_page_free_list()和check_page_alloc()将会测试你的物理页分配器。
boot_alloc
lab2中给出的boot_alloc如下:
1 | // This simple physical memory allocator is used only while JOS is setting |
函数功能
根据注释中的提示,我们可以得知这个函数功能如下:
- 当
n > 0时,分配足以容纳nbytes的物理内存页,并返回内核虚拟地址,不需要初始化;如果不够了,系统调用panic打印错误信息。 - 当
n == 0时,直接返回下一个空闲页的地址
实现准备
为了实现上面的功能,我们需要思考如下问题:
- 如何确定nextfree的位置在哪里?
- 如何确定是否有足够的内存用于分配
首先,我们来回顾一下我们的内存模型:忽略底部的用于BIOS、硬件以及bootloader的部分,内核实际是加载到0x00100000中的,linker会自动为内核镜像分配内存,所以内存的使用是从0x00100000这个地址向上增长的。那么最大内存是多少呢?这取决于硬件中实际内存的容量,在pmap.c中,我们有一个i386_detect_memory()函数,用于检测内存的大小,其中有一个npages全局变量保存了以页为单位的可用内存的数目。实际实验中npages为32768
1 | +------------------+ <- 0xFFFFFFFF (4GB):这个内存根据实际大小会发生变化 |
下面解决第一个问题,如何确定下一个空闲页的位置在哪里,这里我们先来回顾一下一个程序的虚拟内存模型:
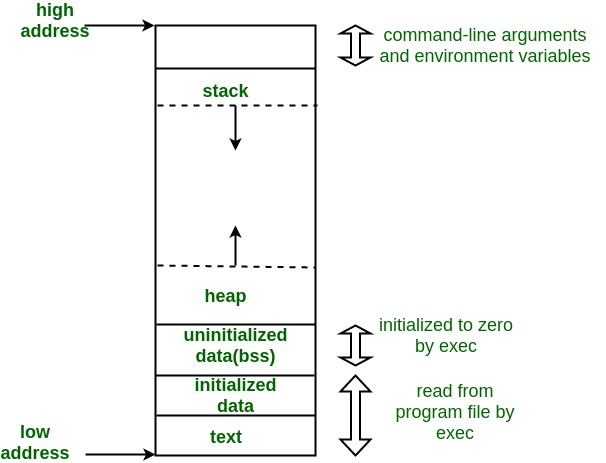
我们需要注意的是:千万不要把操作系统想的太复杂,它就是一个比较特殊的可执行文件,这个可执行文件一定是符合一般的可执行文件的内存分布的,所以肯定也符合上面的虚拟内存模型。我们可以看到,bss段之后就是堆段,也就是我们需要分配的内存所在的位置,而栈段是从内存高地址开始的,并向下增长,所以最后堆段会和栈段发生碰撞,产生stackoverflow等问题,不过这里不是我们需要关注的,我们只需要知道bss段后是heap段即可。所以程序中nextfree第一次被创建并赋值时,其位置在bss段之后。而我们的程序也体现了这一点:
1 | // Initialize nextfree if this is the first time. |
我们注意到nextfree是一个static类型的变量,其生命周期是整个内核的生命周期,而end为bss段的结束,这个是由linker决定的,寻找bss段后第一个nextfree的语句为
1 | nextfree = ROUNDUP((char *) end, PGSIZE); |
ROUNDUP根据注释的提示,可以知道是对齐的作用,所以实际上bss段和堆段之间有一小片(小于一个PGSIZE大小)的内存碎片被浪费掉了。
当我们再次进入boot_alloc,此时nextfree已经不再为空,那么该如何寻找呢?我们现在有需要分配的字节数n和当前地址nextfree,那么下一个空闲的地址的计算如下:
具体计算原理详见:关于内存计算的讲解。所以我们计算nextfree的代码如下:
1 | nextfree = ROUNDUP((char*)(nextfree + n), PGSIZE); |
可以看到,如果nextfree+n不能整除PGSIZE,就会产生内存碎片。
下面我们解决第二个问题,如何确定是否有足够的内存空间。我们现在有npages代表最大可用内存页数,那么npages*PGSIZE就是最大内存容量。而我们现在知道nextfree,由于内存是向上增长的,所以我们只需要用nextfree减去内存起始地址,即可判断是否超过最大可用内存。那么现在的问题是,如何找到起始内存地址。根据i386_detect_memory()我们知道,npages代表的是总内存大小,即从地址0x0开始,到最大的物理内存地址。所以起始地址即为0x0。另外nextfree是虚拟地址,我们还需要转换为物理地址。现在我们可以写出计算是否超过内存容量的代码:
1 | if(PADDR(nextfree) > npages*PGSIZE) // 分配后的内存地址超过了总内存地址 |
具体实现
boot_alloc实现代码如下:
1 | static void * |
mem_init()的第一部分
lab2中给出的mem_init()如下:
1 | void |
函数功能
mem_init()第一部分功能如下:
- 检测物理内存大小
- 创建一个用于保存页表的页
- 分配能容纳npages * struct PageInfo的空间
- 将分配的PageInfo根据内存实际使用情况进行初始化
其中需要我们完成的是第三部分
具体实现
首先我们计算所需的空间大小,为npages * sizeof(struct PageInfo);,然后利用boot_alloc函数分配空间,最后memset初始化,代码比较简单,如下所示:
1 | // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. |
page_init():形成物理内存链表
在分配好了物理内存页表后,我们需要根据内存的实际情况对这些页表进行初始化,标识出空闲的内存,该函数如下所示:
1 | void |
函数功能
上面的函数将所有的物理内存页都初始化为了空闲,但实际上这是不对的,我们需要根据内存的实际使用情况,将其进行初始化,规则如下:
- 将物理页0标注为正在使用
- 将物理页1-npages_basemem标注为空闲
- 物理页IOPHYSMEM/PGSIZE - EXTPHYSMEM/PGSIZE标注为正在使用
- EXTPHYSMEM/PGSIZE之后有一些内存是空闲的,一些是正在使用的
其中,所以我们最后得到的内存页链表如下所示:

我们通过page_free_list,就可以以倒序的形式,遍历所有的空闲内存页。根据内存使用规则,我们可以得到page_init具体实现。
实现准备
为了实现上面的功能,我们需要思考如下问题:
- 非空闲的内存如何处理?
- 在extened memory中,从何处开始是空闲内存?
首先回答第一个问题,非空闲的内存页我们就不将其连接到链表当中了,这些内存有其特定作用,一般不用来作为free mem,所以我们采用一种冷处理的方式。
第二个问题,在扩展内存中,哪些是内核使用的内存?空闲内存是何处开始的?考虑我们写过的函数boot_alloc,当输入为0时,返回下一个空闲页的地址,所以我们可以利用这个函数找到空闲页地址,假设为$p_f$,那么$[p_f/\textrm{PGSIZE},\textrm{npages}]$这一段内存我们都需要进行初始化。这里还有一个问题,boot_alloc返回的是一个指针值,即对应的逻辑地址,我们还需要将这个逻辑地址转换为实际的物理地址。从mem_init中有一个宏函数PADDR,专门完成这个工作,至此,我们的两个任务已经完成。
具体实现
page_free_list实际是一个链表,所以page_init实际就是一个链表初始化的过程
1 | // Initialize page structure and memory free list. |
page_alloc:分配一个物理页
在对所有的可用pages进行初始化后,下一步是写一个分配和释放器,由于page_free_list是一个链表,所以我们的分配和释放器也要有链表的行为。我们先来完成page_alloc,其定义如下:
1 | // Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire |
函数功能
page_alloc的函数功能为分配一个物理页,并返回这个物理页对应PageInfo的地址。在page_alloc中我们将所有的空闲内存都用PageInfo一一对应,并构造了一个page_free_list,所以我们的分配操作是针对这个链表进行的。我们先具体定义page_alloc的流程:
- 如果内存耗尽,返回
NULL - 如果
(alloc_flags & ALLOC_ZERO),将PageInfo对应的物理页清空 - 返回的指针中的
pp_link应当设置为NULL - 不要修改
pp_ref,这个工作交给调用者完成 - 调整
page_free_list的值
针对上面几个功能我们逐一完成。首先第三个和第四个功能很好实现,我们先解决第一个,如何判断内存耗尽?既然page_free_list是一个链表,那么当链表为空时,代表所有的物理页均已分配,所以判断内存耗尽的代码为page_free_list == NULL。
第二个问题,如何将PageInfo对应的物理页清空?为了实现该功能,我们要利用到memset函数,问题是如何找到PageInfo对应的物理页的地址。根据提示,可以使用page2kva实现,清空的大小为一个物理页的大小,第二个问题也解决了。
最后一个问题,如何调整page_free_list的值,这个过程是一个链表删除头节点的过程,先用一个节点保存头节点,然后head指向head->next即可。
具体实现
根据我们总结的函数功能,可以得到page_alloc实现如下:
1 | struct PageInfo * |
page_free:释放物理页
一旦一个物理页用完,我们应当重新将其添加至page_free_list中,所以page_free的过程本质上是一个在链表头插入节点的过程。物理页用完的标准是pp_ref == 0 && pp_link == NULL。如果pp_ref不为0,代表还有对象在使用这块内存,就不应该释放;如果pp_link != NULL,说明这个物理页后面还有其他页,一旦将这个页释放,后面的页也会连带着找不到,会造成内存泄漏。所以也不能释放。page_free比较简单,这里直接给出实现
1 | // Return a page to the free list. |
至此,我们完成了Part1的全部内容,运行make grade可以拿到10分。
第二部分:虚拟地址
虚拟、线性以及物理地址
这一部分的实验文档阅读总结详见关于地址的讲解
练习3:使用QEMU查看物理内存
GDB只能访问虚拟内存,如果我们想要访问物理内存,可以使用QEMU的monitor commands。进入和退出monitor的方法为在QEMU界面为在运行QEMU的shell中按下ctrl-a c。使用xp命令可以查看对应的物理内存。
1 | (qemu) xp 0x0010000c |
使用gdb查看对应的虚拟内存
1 | (gdb) x/x 0xf010000c |
课程提供的QEMU有一个info pg命令,可以打印当前页表的信息。但是我用的是原生的QEMU,没有此命令,有一个info mem命令能够查看当前物理地址到虚拟地址的映射情况以及读写权限
1 | (qemu) info mem |
地址类型
由于JOS经常需要将地址视为整数进行操作,为了区分物理和虚拟地址,JOS提供了两种类型,分别是uintptr_t和physaddr_t,实际都是uint32_t。JOS能够将uintptr_t转换为指针类型然后解引用,但是不能解引用一个物理地址,因为保护模式下只能访问虚拟地址。如果试图解引用一个物理地址,MMU也会把这个物理地址作为虚拟地址来处理。
在有些情况下,如果只知道物理地址,例如想要添加一个页表映射,此时需要分配一块物理内存存放页字典。但是kernel不能进行虚拟地址的转换,因此无法直接加载物理地址。JOS之所以将物理地址0x00000000映射至0xf0000000,就是为了解决内核只知道物理地址的情况。为了将物理地址转换为虚拟地址,内核需要将物理地址加上0xf0000000,然后对虚拟地址进行操作。JOS提供了函数KADDR(pa)实现转换过程。同样的,PADDR(va)实现了物理地址到虚拟地址的转换。
引用计数
在接下来的实验中,我们会遇到一个物理地址同时映射到多个虚拟地址的情况(或者说是一个物理地址处于多个不同环境的地址空间)。此时我们需要一个计数器记录一个物理页的被使用情况。这个计数器是PageInfo结构体下的pp_ref。当pp_ref为0时,这个内存可以释放。一般情况下,pp_ref应当等于低于UTOP的物理页出现在页表中的次数(高于UTOP的物理内存在boot期间被kernel设置,并且永不释放,所以不需要对其计数)。注意,page_alloc并不会修改引用计数,该函数返回的页引用总是0。
页表管理
现在写一些关于页表管理的函数:插入和移出线性地址到物理地址的映射,同时在需要的情况下创建页表页。
练习4
完成如下函数的代码,check_page()将会检查函数的正确性:
1 | pgdir_walk():页目录中查找 |
pgdir_walk()
函数原型
函数功能
根据虚拟地址找到对应的pte的指针,用图来描述就是下面这张
具体实现
1 | pte_t * |
boot_map_region()
函数原型
1 | // |
函数功能
这个函数的功能是将虚拟地址[va, va+size)映射至物理地址[pa, pa+size),pte的权限设置为perm|PTE_P。本质上是多叉树的范围赋值。
函数实现
1 | static void |
page_lookup()
函数原型
1 | // |
函数功能
返回va对应的物理页
函数实现
1 | struct PageInfo * |
修改
上面的函数有两个问题:
- 仅判断
pte为空是不行的,还要判断*pte是否为0 - 要判断
pte是否在合适的范围之内,即PPN(*pte) <= npage
1 | struct PageInfo * |
page_remove()
函数原型
1 | // |
函数功能
解除物理页和虚拟地址的映射关系
函数实现
1 | void |
page_insert()
函数原型
1 | // |
函数功能
将物理页pp映射至虚拟地址va,实际上是在多叉树中插入
函数实现
1 | int |
细节:关于边界条件的处理
当同一个pp被重新插入至相同pgdir的相同pte,会发生什么事情?按照上面的代码,首先,pp会被remove,当被remove之后,pp会被回收,而下面的代码又回去利用被回收的pp,因此会造成访问非法内存的问题。正确的方法是将pp->pp_ref++放置在回收语句之前,这样一增一减正好抵消,pp不会被回收掉。而如果是不同的pp,则不受影响。
第三部分:内核地址空间
JOS对内存进行了划分,虚拟地址低部分为用户空间,高部分为内核(约256MB),分界线是ULIM: 0xef800000,给操作系统留下了大约256MB的空间。在ULIM往上,用户没有访问权限。
权限和错误处理
由于内核和用户代码都在地址空间中,因此我们需要权限管理,使用户只能访问自己的地址空间。首先,我们先进行一个划分:
- 高于
ULIM:用户无权访问 [UTOP, ULIM):用户和内核只能读,这一段用于保存向用户开放的内核只读数据- 低于
UTOP:用户可用空间
内核地址空间初始化
练习5:完成mem_init()中check_page()之前的代码
在这个练习中,我们需要建立内核代码中相关的物理地址和虚拟地址之间的映射,建立过程使用上一节实现的boot_map_region函数即可。映射过程已经由注释给出了提示,相关代码如下:
1 | ////////////////////////////////////////////////////////////////////// |
上述三行分别完成了页表、内核栈和内核的映射,可以看到低物理地址的内核被映射至了高虚拟地址上。需要注意的是,在建立内核栈时,创建了一段未映射的缓冲区,大小是PTSIZE-KSTKSIZE,内核栈如果访问了这段区域,会导致错误。完成之后本次实验的基础部分已经完成,make grade命令会显示全部通过。
问题
整理内存映射表
我们已经在内核中部分建立起虚拟地址到物理地址的映射,现在,根据已经建立的映射关系尽可能填写下面的表格
| Entry | Base Virtual Address | Points to (logically): |
|---|---|---|
| 1023 | ? | Page table for top 4MB of phys memory |
| 1022 | ? | ? |
| . | 0xf0000000(KERNBASE) | |
| 958 | 0xef800000(ULIM) | limit between user and kernel |
| 957 | ? | |
| 956 | 0xef000000(UPAGES) | Read Only pages |
| 2 | 0x00800000 | ? |
| 1 | 0x00400000 | ? |
| 0 | 0x00000000 | [see next question] |
内存保护机制
Q:我们将内核和用户进程放在同一个地址空间中,为何用户进程无法读写内核内存。为何用户无权访问
A:因为我们对虚拟内存也进行了划分,按照ULIM为分界线,向上为内核区域,用户无权限访问。这一机制是靠Current Privilege Level实现的,cs寄存器的两位描述了当前程序的权限,linux使用了两位,分别是内核态(0)和用户态(3)。
操作系统能支持的最大内存是多少?
这个问题问的有歧义,应该问内核占用的物理地址最大为多少。由于内核虚拟地址范围是[0xF0000000, 0xFFFFFFFF],所以大小为0x0FFFFFFF,共256MB,操作系统理论上最大为256MB,超了的话32位地址无法映射。
用于管理内存的空间开销是多少?如何降低这个开销?
首先,我们有一个页目录,大小是一个页。
其次,我们使用了一个pages结构体数组,用于对页进行保存,这个数组的大小是npages * sizeof(struct PageInfo),具体值为32768*8B /PGSIZE=64个页。总共65个页,当然在后续加入用户进程后,维护页表还需要额外的内存空间。
我能想到的降低开销的方法是加大页的空间,例如使用2MB或4MB的页,这样可以降低页表数量,节约一部分开销。
地址切换问题
再次查看kern/entry.S 和kern/entrypgdir.c两个文件,当我们开启页映射后,EIP仍处于低地址空间。那么什么时候开始EIP位于高地址空间呢?
为了解决这个问题,我们开启gdb对内核启动的初始阶段进行调试,设置断点br *0x0010000c,然后跳转到entry,这一段的汇编如下:
1 | 0x100015 mov $0x118000,%eax # 加载页目录,entrypgdir 位于0x11800,保存在了cr3寄存器中 |
是什么机制使得我们在开启页映射到跳转至高地址这段区间内,仍然能够执行位于低地址的指令?
为了解决这个问题,我们需要查看CR0寄存器,开启分页后CR0寄存器的值为0x80010001,即
1 | cr0 = 1000, 0000, 0000, 0001, 0000, 0000, 0000, 0001 |
翻译过来就是,使能页映射;使用CR3寄存器;不禁用cache,不禁用write-through cache;位于保护模式;开启写保护。没什么特别的,然后我们看下kern/entrypgdir.c。在这个文件中 ,我们找到了如下代码:
1 | pde_t entry_pgdir[NPDENTRIES] = { |
看到这里应该就明白了,实际上我们是进行了一个双重映射,将虚拟地址的[0, 4MB)和[KERNBASE, KERNBASE+4MB)都映射到了物理地址的[0, 4MB),所以我们能够在开启页映射后,依然在低地址空间执行,但是实际上这里的低地址空间是虚拟地址的低地址空间。VA’[0, 4MB) to PA [0, 4MB)这个映射只使用了这一次,算是做的一点小小的妥协吧。
附录
物理内存布局
在经过实验一和实验二后,我们对于操作系统物理内存的布局已经有了一些基本了解,现在我们总结一下已经确定的物理内存布局图:

绿色的就是几个比较关键部分的内存布局。
内存映射关系
现在我们来总结一下内存映射关系:
一些重要的函数及计算
i386_detect_memory
这个函数负责获取实际的内存大小,里面定义了totalmem、basemem两个变量分别表示总内存及基本内存,在实验中,这些变量的值如下:
1 | totalmem = 131072(KB) //0x08000000 |
所以总的物理页计算为:
1 | npages = totalmem/(PGSIZE/1024); // npages = 32768 |
共有32768个物理页。
check_page_free_list(bool only_low_memory)
这个函数的作用是检查page_free_list所指向的页面都是有效的,进入后首先判断page_free_list是否为空,为空则无效,随后进入下面一段代码
1 | if (only_low_memory) { |
这段代码比较迷惑,为了解释其功能,我们先要明确PDX以及page2pa的作用,先看page2pa,其函数原型为:
1 | page2pa(struct PageInfo *pp){ |
这个函数的作用是找到pp所对应的PageInfo指向的具体的物理页,由于一个物理页的大小为4096,所以由页序号转到物理地址的计算公式为$(page1 - start_page)\times PGSIZE=(page1 - start_page)<<PGSHIFT$。
PDX的作用是获得线性地址的一部分,这里不展开说了。
调试过程
boot_alloc 调试过程
使用GDB进入boot_alloc后,得到nextfree的起始地址为0xf0115000,根据内存大小,可以知道内存最大物理地址为0x08000000,所以总可用空间为0x7EEB000。