Hi siri! Help me to copy a siri.
简介
进程的定义
进程是系统进行资源分配与调度的基本单位,具体一点讲,进程就是活动的程序,进程是暂时的,程序是永久的。
进程的组成
作为一个被加载到内存中的活动的程序,进程由五个部分组成,即将内存进行分段后,分配给某一个进程,分段示意图如下:
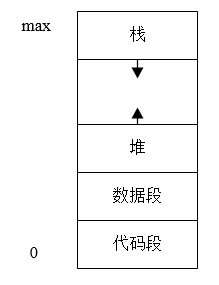
进程包含了正在运行的一个程序的所有状态信息:
- 代码
- 数据
- 状态寄存器:CPU状态CR0、指令指针IP
- 通用寄存器:AX、BX、CX…
- 进程占用系统资源:已分配内存、打开文件
进程特点
进程包含动态性、并发性、独立性和制约性(因访问共享数据/资源产生的制约)
进程描述符(Process Control Block,PCB)
进程描述符实际上保存了进程的控制信息,这些信息包括:调度和状态信息、进程间通信信息、存储管理信息、进程使用资源信息以及有关数据结构连接信息(与PCB相关的进程队列)。
进程描述符内容
进程描述符(或者叫进程控制块PCB)是一个对进程进行管理的数据结构,在进程创建时一同建立并严格一一对应。在Linux系统下,PCB是一个task_struct类型结构,包含了和进程相关的若干信息。具体内容包括:
- 进程状态
- 进程ID
- 程序计数器
- 寄存器
- 内存限制
- 打开的文件
- 优先级
- …
有些内容会随着进程状态改变而改变,而有些内容会频繁发生更新。上面的信息可以分为几类:
- 标识信息
- 状态信息
- 资源信息
- 现场保护信息
- 队列信息
1 | struct process{ |
在上面的代码中,memory_map是一个比较重要的数据结构,具体如下:
1 | struct memory_map{ |
进程描述符工作过程
当一个进程处于运行态时,CPU的寄存器会保存PCB,而当发生进程切换,操作系统会保存当前进程的状态,然后切换到另一个进程,同时CPU中保存的PCB也会发生变化。
PCB组织结构
PCB的组织结构一般采用链表或索引表组成,在实验中是使用链表进行组织。内核将相同状态的进程PCB放置在一个队列中。而在实际应用中,由于链表索引困难,因此采用哈希链表,将大链表拆分,每一个部分进行哈希处理,这样可以使索引变为$O(m)$,其中$m$为每个部分的平均长度
进程的状态
轻重进程状态
由于进程中可能有多个线程在执行,因此我们的PCB可以被进一步分割,分为轻重进程状态:
- 轻进程状态:随着线程切换而改变的,例如signal mask和系统调用的参数等
- 重进程状态:不随线程切换而改变的,即所有线程共有的,例如虚拟地址映射
生命周期
graph TB
node1((new))
node2((ready))
node3((running))
node4((waiting))
node5((end))
node1--admit-->node2
node2--调度-->node3
node3--抢占/中断或时间片用完-->node2
node3--IO或事件等待-->node4
node4--IO或事件完成-->node2
node3--退出-->node5
- 新生(new):当进程被创建后,它处于新生态,此时等待操作系统进行调度
- 就绪(ready):进程已处于准备好运行的状态,即进程已分配到除CPU外的所有必要资源后,只要再获得CPU,便可立即执行。就绪进程位于就绪队列中。当时间片结束之后,进程处于就绪态而非等待态。
- 执行(running):进程已经获得CPU,程序正在执行状态
- 阻塞(waiting):正在执行的进程由于发生某事件(如I/O请求、申请缓冲区失败等)暂时无法继续执行的状态,等待是进程内部原因导致的
- 结束(end):进程僵死或死亡,要将资源还回去。进程结束可能是正常退出、错误退出、致命错误或被其他进程杀死
除此之外,进程还有一个特殊的状态叫进程挂起,进程挂起涉及虚拟内存,即将处于等待或就绪的进程保存在外存当中,而当进程开始运行,再从外寸调回内存。实际上是时间换空间的做法。挂起即把进程从内存转到外存。这里稍微了解一下4。
内存时的挂起状态包括:
- 等待到等待挂起
- 就绪到就绪挂起
- 运行到就绪挂起:对于抢占式的系统,高优先级抢占低优先级,且没有足够内存空间
外存时的挂起状态
三状态模型
将进程状态最重要的部分进行抽象,我们可以得到进程的三状态模型,即就绪、运行和等待。因为这些是最频繁发生且非一次性的,而创建和退出是一次性的。
状态队列
根据进程的状态,可以创造不同的队列保存不同状态的进程,进程状态的切换实际上是队列的切换。运行态的进程没有队列。
Linux上的进程状态
linux上的进程状态可以进一步细分为7个:
产生原因
当一个子进程结束时,并没有真正被销毁,而是留下了一个成为僵尸进程的数据结构,包含退出码和CPU等待时间等数据,这些数据最终会被传递给父进程。而父进程会起到为其收尸的作用,收尸的情况可能有两种
- 父进程调用wait或waitpid等待子进程结束
- 父进程结束后由init进程销毁
但如果父进程是一个不会结束的循环进程,就会导致僵尸进程持续存在,虽然一个僵尸进程几乎不占用系统资源,但是如果多了还是会给系统带来影响,那么我们应该如何处理僵尸进程呢?
处理僵尸进程的方法
- 终止
首先,我们先找到僵尸进程的父进程,shell命令如下:
1 | ps -ef | grep defunct_process_pid |
然后将父进程杀死,连带着僵尸进程也会被杀死。
- 预防
上面给出的方法属于被动解决僵尸进程,显然我们是不满意的,我们还希望能够提供自动预防僵尸进程产生的方法,这里提供三个
- 父进程调用函数
signal(SIGCHLD,SIG_IGN);令系统自动回收子进程 - 用waitpid等待子进程返回
进程控制
上下文切换
当CPU从执行进程A切换至执行进程B时,发生了上下文的切换。当发生上下文切换时,操作系统必须高效地中断并保存现场,决定下一个进程,并释放将要执行的进程。所以进程切换要做两件事:
- 暂停当前进程,从运行态切换为其它态
- 调度另一个进程,从就绪态变为运行态
一般进程的切换频率为10-15ms,切换速度非常快,因此一般使用汇编实现。
Task State Segment
32-bit TSS的结构
Linux为每一个CPU设置了单独的TSS,来保存任务状态,并使用一个32位TSS descriptor来指向TSS的起始地址。32-bit的TSS的结构如下图所示:

TSS中主要包含静态和动态部分。其中动态部分在程序切换时由处理器进行更新;而静态部分在任务创建时被设置,处理器一般只读。
- 动态:通用寄存器、段寄存器、EFLAGS、EIP以及前一个任务的TSS的选择符
- 静态:任务的LDT的段选择符、CR3寄存器、不同优先级的栈指针及偏移量
TSS保存了不同特权级下的堆栈信息,当发生堆栈切换,被调用者的堆栈的SS和ESP从此处取出,从而产生特权级的切换,由于从低特权级向高特权级转换,故TSS没有最低特权级的堆栈信息。
TSS Descriptor5
TSSD 记录了TSS的位置、大小以及相关属性,TSSD存放在GDT中,GDT的基址存放在每个CPU的gdtr寄存器中,TSSD的格式如下图所示:
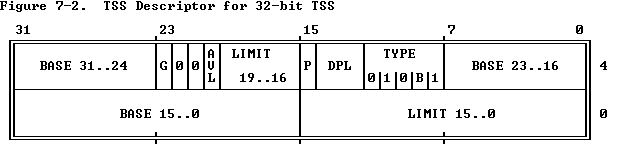
关键字段的功能如下:
- Base Address:TSS线性地址的第一个Byte
- Limit:TSS最大偏移量
- DPL:TSSD的特权级
- G:TSS大小粒度(0-byte粒度,1-4KB粒度)
- P:TSS是否在物理内存中
- B(busy flag):当前任务是否busy(B=1),一个忙任务表示正在运行或挂起的任务
TSS Selector
TSS Selector用于在GDT中寻找特定的TSSD,实际上就是数组的一个偏移量。
切换过程
进程切换分为两步:
- 切换页目录,安装新的地址空间
- 切换内核栈和硬件上下文(线程只做这一步)
进程切换过程如下图所示:
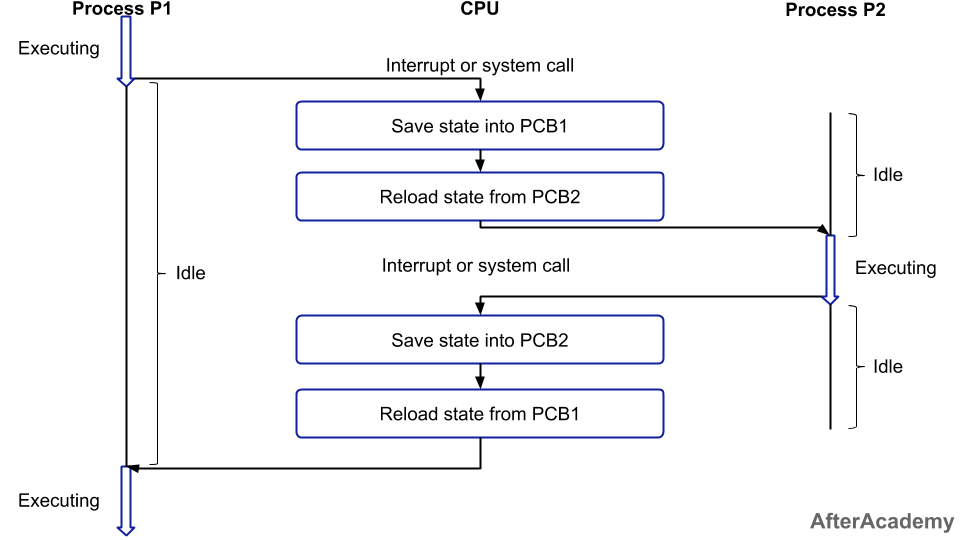
具体的切换流程如下:
graph TB
node1[开始调度:cpu_idle]
node2[清除调度标志:schedule]
node3[查找就绪进程:还有可能查到自己]
node4[修改进程状态]
node5[进程切换:switch_to]
node1-->node2
node2-->node3
node3-->node4
node4-->node5
node5-->node6
CPU调度器
CPU调度器决定何时执行何进程多长时间。在设计调度器时,我们需要考虑进程应该执行多长时间,或者说调度频率应该有多高。这里我们引入CPU有效工作占比$r_e$的概念,其公式为:
其中$t_p$为进程工作时间,$T$为一个调度周期总时间,$t_s$为上下文切换时间。从公式中可见,如果切换过于频繁或者上下文切换时间过长,那么会导致有效工作率下降
消耗
进程切换后,虚拟内存空间发生了变化,这一步是由操作系统内核完成的。进程切换是有损耗的,除了时间损耗外,还有两个关于空间的损耗,所以我们要控制进程切换的频率
- 寄存器中的内容需要发生变化;
- 上下文切换会扰乱CPU Cache,已经缓存的进程A的数据在一瞬间全部作废,换成进程B。(cold cache)
进程创建
Linux下进程创建系统调用fork
fork函数会创建一个新进程,和调用fork的进程几乎一致,两个进程都会继续运行,fork函数返回值如下:
- 子进程中成功的fork调用返回0
- 父进程返回子进程pid,出现错误返回负值
fork 使用方法及例子
1 | int pid = fork(); |
如果fork正确,上面的代码运行结果可能为:
1 | parent:child = 1234 |
或者
1 | child exiting |
取决于子进程和父进程谁先获得执行权
- fork一个新进程
- 使用exec()载入一个新的应用程序,替换当前进程,这样就可以派生并执行一个不同的进程
fork计算
fork一次会产生两个进程,而循环$n$次进行fork,会产生$2^n$个进程
fork的演进
早期的Unix系统fork会老老实实复制一份新数据,开销很大。但是后来为了提高效率,只在进行写操作时复制。在linux下是vfork,即轻量级fork,将内存复制延迟到应用时。
fork与多线程
考虑这个问题,在一个多线程的进程中进行fork(听起来就蛋疼的要命)。在POSIX标准中,其行为如下:
- 复制整个空间的写数据
- 仅复制当前线程到子进程,其余线程全部蒸发
这产生了一个严重问题,锁被复制,但是线程没了,这些锁就成为了孤儿锁,没有主人,无法被解锁,会导致程序发生严重死锁。
fork与文件
使用fork创建新的进程后,子进程会拷贝父进程的文件描述符表,但是父子进程会共享文件偏移量,考虑下面的例子:
1 | if(fork() == 0){ |
结束后文件描述符1指向的文件会包含数据"hello world",因为有wait()的存在,子进程会先于父进程进行写操作,改变文件的偏移量;而父进程会在此基础上进行写操作
创建空闲进程
如果没有用户进程,那么操作系统会怎么处理呢?操作系统会创建一个空闲进程,然后运行这个进程。
创建第一个内核线程
进程加载
使用exec加载进程
进程加载允许进程加载一个完全不同的程序,并从main开始执行,程序的加载和执行的系统调用是exec()。exec允许指定启动参数。当exec调用成功后,会替换调用进程的内存,重写代码段、堆栈和堆,并载入一个新内存镜像。exec在shell中很常见,用于执行用户的指令
exec 使用方法及例子
exec 接收两个参数,可执行文件的名称以及字符串格式的参数数组,exec如果成功执行,不会返回。
1 | char *argv[3]; |
fork和exec共同使用
1 | int pid = fork(); |
exec实现
exec的实现可以分为三个函数
- sys_exec:获取创建进程的相应参数
- do_execve:创建新进程所需要的段结构
- load_icode:识别可执行文件格式,并加载到内存中
进程使用
进程树
在大多数操作系统中,进程创建的过程可以被视为一个树形结构,首先有一个根进程在系统启动后被创建,然后这个根进程创建了一些初始进程,这些初始进程随后又开始工作,创建了更多的工作进程。以linux为例,这个过程如下所示:
graph TB
node["idle(0)"]
node1["init(1)"]
node2["pageout"]
node3["shell"]
node4["ls"]
node5["emacs"]
node6["..."]
node-->node1
node-->node2
node1-->node3
node3-->node4
node3-->node5
node5-->node6
Linux的进程祖先为进程0,即idle进程,该进程使用静态分配的数据结构,而其他进程数据结构都是动态的。而init进程由start_kernel()创建。操作系统外层的其他所有的进程都由init创建。
进程同步
进程同步:指对多个相关进程在执行次序上进行协调,以使并发执行的进程之间能有效地共享资源和相互合作,从而使程序的执行具有可再现性,同步机制如下:
- 空闲切换
- 忙则等待(保证临界区互斥访问)
- 有限等待(等待有限时间,避免死等)
- 让权等待(当无法访问临界区时,应当释放处理机,以免陷入忙等)
IO
当进程执行过程中,会执行IO过程,而IO往往是很慢的,所以CPU需要考虑IO对进程的影响,CPU处理进程中的IO操作的模型如下:
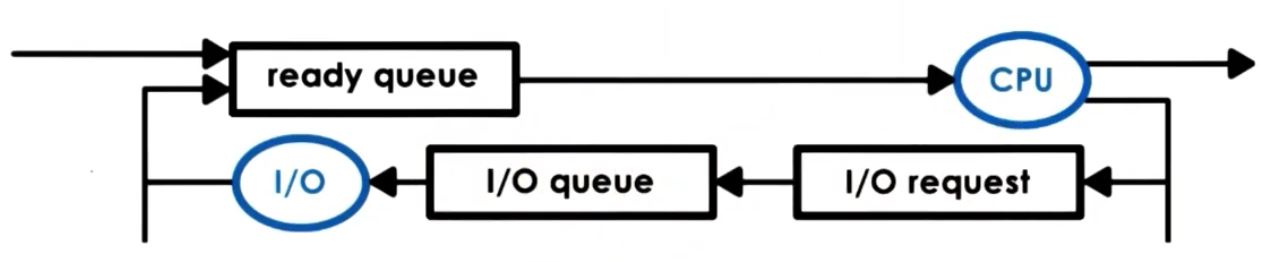
在IO请求时,正在执行的进程将进入等待队列中。
进程活动模型
现在我们对进程的活动模型进行一个总结,如下图所示:
![]()
从上图中可以看到,当发生IO请求、时间片耗尽、fork线程或发生中断时,都有可能导致进程从运行态进入等待队列中。
进程通信方式(Inter Process Communication, IPC)
通信方式包括无名管道、有名管道、信号、共享内存、消息队列、信号量等。可以分为高级与低级两种。由于每个进程拥有自己的用户地址空间,因此进程间的全局变量是不可变的,所以进程间通信必须经过内核。
高级通信方式
- 共享内存:最快的进程间通信方式,例如剪贴板,共享内存是完全在用户态的,操作系统不需要干预,这也导致没有合适的系统调用帮助我们进行通信。
- 消息传递系统:类似于信号—槽系统,是一种无连接不可靠的单向数据传输系统
- 管道通信系统:管道是单向的、先进先出的、无结构的、固定大小的字节流,它把一个进程的标准输出和另一个进程的标准输入连接在一起。写进程在管道的尾端写入数据,读进程在管道的道端读出数据。数据读出后将从管道中移走,其它读进程都不能再读到这些数据。管道提供了简单的流控制机制。进程试图读空管道时,在有数据写入管道前,进程将一直阻塞。同样地,管道已经满时,进程再试图写管道,在其它进程从管道中移走数据之前,写进程将一直阻塞。
- 匿名管道:未命名的、单向管道,通过父进程和一个子进程之间传输数据。匿名管道只能实现本地机器上两个进程之间的通信,而不能实现跨网络的通信。
- 命名管道:不仅可以在本机上实现两个进程间的通信,还可以跨网络实现两个进程间的通信。
- 套接字:套接字也是一种进程间通信机制,与其它通信机制不同的是,它可用于不同机器间的进程通信
- 消息队列:是一个在系统内核中用来保存消息的队列,它在系统内核中是以消息链表的形式出现的。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点
低级通信方式:
- 信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其它进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段
创建进程的方式
进程创建有fork和exec两种方式,其特点分别如下:
- fork复制进程,然后两个进程开始分别运行
- exec在现有进程上下文中运行可执行文件,替换以前的可执行文件
进程相关系统调用
| 名称 | 功能 |
|---|---|
| kill | 向进程发送信号 |
| setgid | 设置进程的组id |
| exec | 执行给定的文件,不会改变进程号,只会以另一个可执行文件替换当前程序 |
exec族
execv
- 原型
execv的原型如下:
1 |
|
- 输入
- path:可执行文件路径,
- constargv:传递给应用程序的参数列表,
constargv[0]为应用程序本身的名字,最后一个参数应当为NULL