Listen, the tree is growing silently
介绍
What and why tree
- 一种层次数据结构
- 节点有值和位置两个属性
- 有根节点,每个节点可以有左子树和右子树
在插入、删除、搜索方面,树相较于数组和链表O(n),更有优势O(log(n))。
树的术语
- Root 根: 没有parent的节点
- Edge 枝: 父子间的连接
- Leaf 叶: 没有child的节点
- sibling 兄弟: 有相同parent的节点
- ancestor 祖先: 一个节点的父亲,爷爷、祖宗
- Depth of node 节点深度: 从一个节点到根节点的路径长度
- Height of node 节点高度: 从一个节点到最深的节点的路径长度(越往下越深)
- Height of a tree 树高: 即根节点的高度
- 层数(深度):规定根节点在1层,其他任意节点层数为父节点层数+1
- predecessor 前任: 将树的各个节点以顺序方式组织,则某个节点前面的相邻节点叫做该节点的前任,例如一个树为:
1
40,50,60,70,80,90,100
那么值为60的节点前任就是50
- successor 继任:
和前任类似,只是后面的相邻节点
树的组成
一个二叉树包含左右子节点和键值,其类如下所示:
1 | class TreeNode { |
二叉树基本知识
二叉树就是最多只能有两个子节点的树。本章讨论二叉查找树,即左子树节点值<根节点<右子树节点值,二叉树是一个数据结构家族(二叉搜索树BST,堆树,AVL树,红黑树,语法树,霍夫曼编码树等等)。
二叉树应用在特定的问题中,例如霍夫曼编码、优先队列及表达式解析。
二叉树性质
性质1:在二叉树第$i$层至多$2^{(i-1)}$个节点
证明过程采用归纳法
- $i=1$时只有根节点,显然成立
- 设对所有$j$,$i>j\ge1$均有命题成立,第$j$层至多$2^{j-1}$个节点
- 由归纳假设,第$i-1$层至多$2^{i-2}$个节点
- 由于每个节点度至多为2,故第$i$层最大节点数为$i-1$层节点数的2倍,即$2\times2^{i-2}=2^{i-1}$
性质2:深度为$k$的二叉树至多有$2^k-1$个节点
只需将每一层最大节点数相加即可
性质3:具有$n$个
二叉树的种类
- 严格二叉树: 每个节点要么有两个子节点,要么没有(要么不生,要么二胎)
- 满二叉树: 每个非叶节点有两个子节点,所有叶节点位于同一层
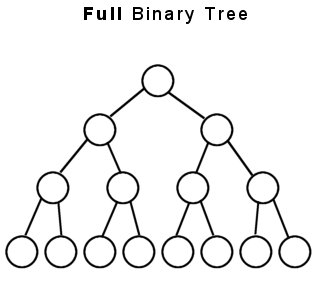
完全二叉树: 所有层都满填充,除了最后一层,并且最后一层节点尽可能靠左
二叉树的实现
二叉树可以用或链表或数组实现(链表更方便)
用链表实现的树如下图所示:
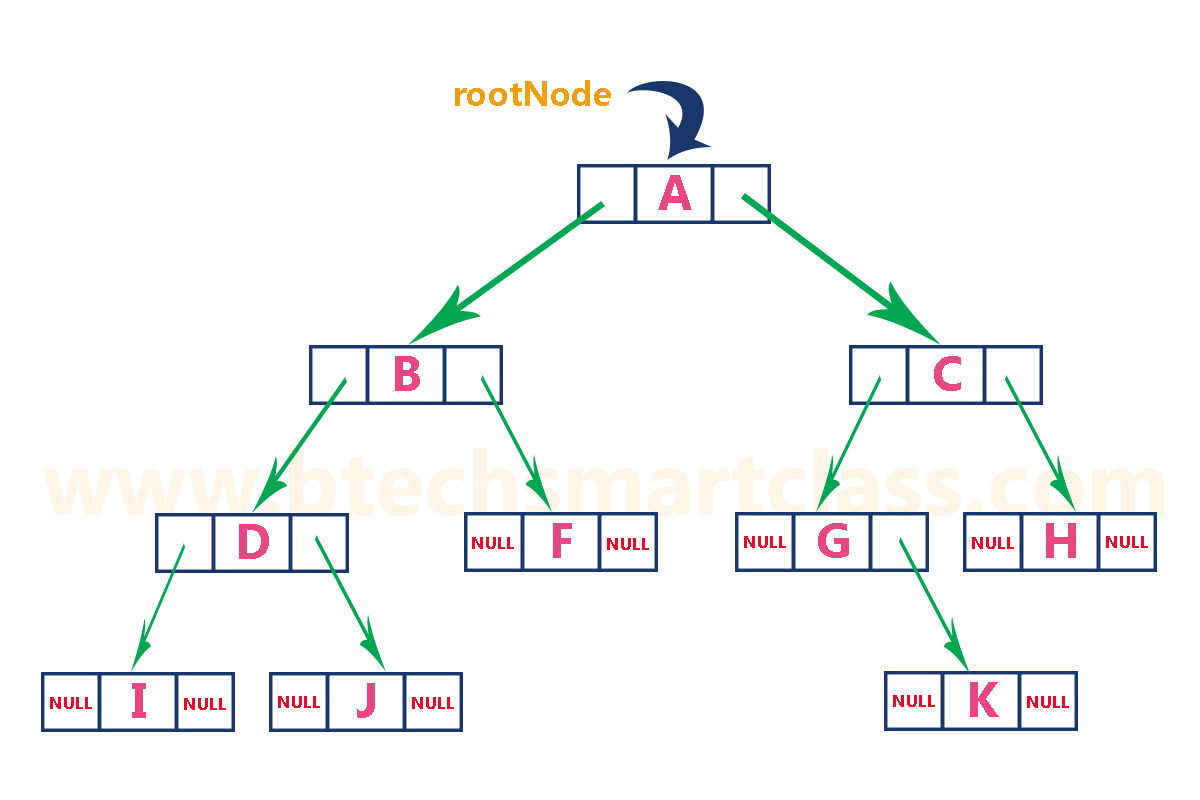
每个节点包括数据、左指针和右指针。
用数组实现的树如下图所示:
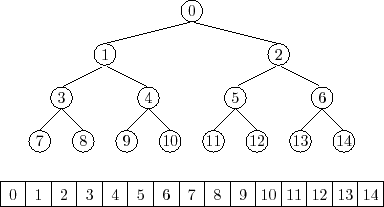
如何表示每个节点在数组中的位置呢,我们使用如下策略,首先,根节点放置在数组下标为1的位置(不是0,为了方便计算),左右节点根据父节点下标,按照下面的公式计算位置:
- 左节点: array[2x]
- 右节点: array[2x + 1]
其中x是父节点在数组中的位置。
二叉树的操作
递归
二叉树最重要的一个操作即为递归操作,下面的操作基本上都是由二叉树的递归操作演变来的,故二叉树的递归操作的框架需要掌握。
1 | int dfs(TreeNode root) { |
六个操作:创建、插入节点、删除节点、搜索、遍历和删除树
创建
create(): 创建一个空树对象
时间与空间复杂度都是$O(1)$
leetcode 654:根据已有数组创建符合条件的树
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
二叉树的根是数组中的最大元素。
左子树是通过数组中最大值左边部分构造出的最大二叉树。
右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
1 | 输入:[3,2,1,6,0,5] |
解答:
1 | /** |
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]返回如下的二叉树(假设树中没有重复节点):
3
/ \
9 20
/ \
15 7
这道题目思路不难,但是写法上有一些需要注意的事情,下面结合代码对本题进行讲解。
思路
- 从前序遍历可以获得根节点,前序遍历为[根节点, [左子树], [右子树]]
- 从中序遍历可以获得左右子树以及其长度,中序遍历为[[左子树], 根节点, [右子树]]
代码如下
1 | TreeNode* helper(int pre_start, |
遍历
这一部分内容比较多,请参考16.4节
traverse(): 遍历树,将树线性化,每个节点只访问一次
遍历树的方式分为两大种,深度优先与广度优先深度优先(按照根的位置进行遍历)
递归法
- 前序(preorder)遍历:从根开始,先左子树,再右子树,递归进行,第一个肯定是根节点
- 中序(inorder)遍历: 先左子树,再访问根,最后右子树(对二叉搜索树进行中序遍历可以输出一个升序数组(或降序,只要按照右中左的顺序即可)),中序遍历实际上就是先探到树底部,然后再自底向上依次对节点进行处理。在中序遍历中,根节点的两边就可以分出左右子树。
前序和中序可以唯一确定二叉树,后序不行
- 后序(postorder)遍历: 先左子树,再右子树,最后访问根节点,最后一个肯定是根节点
前中后序的递归遍历:
1 | //前序 |
前序应用
由于前序遍历先对节点值判断,因此前序遍历可以用在判断两棵树的结构是否相同上。
例题1 LeetCode 100 判断两树是否相同
1 | bool isSameTree(TreeNode* p, TreeNode* q) { |
例题2 LeetCode 面试题26 树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构),B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
1 | 3 |
给定的树 B:
1 | 4 |
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
思路
首先处理特例,当A或B为空时,直接返回false。然后如果树B是树A的字结构,必须满足三种情况,用||进行连接
- 以节点A为根节点的树包含树B:这里我们不妨写一个dfs函数专门进行判断 dfs(A,B);
- 树B是树A的左子树的子结构:
isSubStructure(A->left, B) - 树B是树A的右子树的子结构:
isSubStructure(A->right, B)
在dfs中,又对应四种情况
- 如果节点B为空,说明B已经匹配完成,即越过叶子节点,返回true
- 如果节点A为空,说明已经越过A的叶子节点,返回false
- 当A和B节点值不同,说明匹配失败,返回false
- 当A和B节点值相同,那么继续匹配A左B左,A右B右,即dfs(A->left,B->left) && dfs(A->right, B->right)
迭代法
用递归很方便,考虑使用迭代实现深度优先搜索呢?将递归改为迭代,往往要用到栈或队列(广度优先算法),实例详见2,非递归的版本要比递归的复杂许多。
1 | //中序遍历 |
下面是前序操作的,和中序略有区别,压栈要先压右孩子再压左孩子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23//如果可以的话,尽量使用前序遍历,因为比较简单
template<typename T>
void BST<T>::preorder(){
stack<BSTNode<T> *> tree_stack;
BSTNode<T> *p = root;
if(p!=nullptr){
tree_stack.push(p);
while(!tree_stack.empty()){
//访问
p = tree_stack.top();
tree_stack.pop();
visit(p);
//压入新节点
if(p->right != nullptr){
tree_stack.push(p->right);
}
if(p->left != nullptr){
tree_stack.push(p->left);
}
}
}
}
后序操作,后序操作需要用到两个栈,类似反复倒水的原理
1 | vector<int> postorderTraversal(TreeNode* root) { |
相关例题
给定二叉树的根节点 root,找出存在于不同节点 A 和 B 之间的最大值 V,其中 V = |A.val - B.val|,且 A 是 B 的祖先。(如果 A 的任何子节点之一为 B,或者 A 的任何子节点是 B 的祖先,那么我们认为 A 是 B 的祖先)
思路
一开始的思路是从每个节点开始,以此访问以该节点作为根节点的树,求最大值,这种方式时间效率太低,看了别人的答案发现可以将祖先节点中的最大值与最小值进行保存,从而直接以当前节点的最大值最小值进行比较即可。
代码
1 | class Solution { |
广度优先(层序遍历)
- 层次(levelorder)遍历: 一层一层逐层从左到右访问,使用queue实现,LeetCode411
1 | /*自顶向下的层次遍历*/ |
复杂度分析
上述遍历方法时间和空间复杂度全部都是$O(n)$,但是得到的树的表示方法不一样。
相关例题
给定二叉树如下:
1 | struct Node { |
填充其每个next指针,让这个指针指向同一层下一个右侧节点,如果找不到,将next指针设置为nullptr。
思路
使用层序遍历可以方便地完成上述内容,但是空间复杂度为$O(N)$,为了进一步降低空间复杂度,我们可以利用已经被连接的next指针进行层内转移,而对于层间转移,我们可以提前设置一个哑节点,指向下一层的最左侧的节点,然后利用该节点进行层间转移
代码
1 | Node* connect(Node* root) { |
给定一个二叉树,返回其结点 垂直方向(从上到下,逐列)遍历的值。如果两个结点在同一行和列,那么顺序则为 从左到右。
思路
在本题中,我们不仅需要找到节点的横向相对位移,同时也要保证节点深度是从小到大排列的,这要求我们使用广度优先搜索进行操作。
代码
1 | class Solution { |
Morris遍历4
Morris遍历可以将非递归遍历中的空间复杂度降低为O(1),该算法利用树的叶节点左右孩子为空,实现空间的压缩
原理
我们以二叉搜索树为例,其中序遍历为1,2,3,4,5,6,7,8,9,10,给定某个节点cur,定义其前序节点pre为遍历过程中得到的序列的前一个节点,例如节点4其前序节点为3。那么我们的问题是如何找到一个节点的前序节点,在Morris遍历中,我们需要实现以下原则:
- 如果左子节点的右子节点指针为空,那么左子节点即为
cur的前序节点 - 如果当前节点无左孩子,且该节点为父节点的右孩子,那么父节点即为前序节点,例如8的前序节点为7
- 如果当前节点无左孩子且该节点为父节点的左孩子,那么它没有前序节点,并且该节点为首节点,例如节点
1
算法
- 根据当前节点找到前序节点,如果前序节点右孩子为空,那么把前序节点右孩子指向当前节点(这样我们可以直接通过前序节点找到当前节点),然后进入当前节点左孩子
- 如果当前节点左孩子为空,打印当前节点,然后进入右孩子
- 如果当前节点的前序节点其右孩子指向了它本身,那么把前序节点的右孩子设置为空,打印当前节点,然后进入右孩子。
代码
1 | void inorderMorrisTraversal(TreeNode *root) { |
专题:根据前中后序中两个推剩余一个
遍历中有一类问题,根据前中序遍历,求后序遍历,假设:
- 前序遍历的顺序是: CABGHEDF(前序确定根节点)
- 中序遍历的顺序是: GHBACDEF(中序确定左右树)
1.前序可知C是根节点,中序可知左子树为GHBA,右子树为DEF。
graph TB
node1((C))
node2((GHBA))
node3((DEF))
node1---node2
node1---node3
2.取出左子树,左子树的前序遍历是:ABGH,中序遍历是:GHBA,可知左子树根节点为A,左子树为GHB,没有右子树
graph TB
node1((C))
node2((A))
node3((DEF))
node4((GBH))
node1---node2
node1---node3
node2---node4
3.以此类推,即可得到完整的树为:
graph TB
node1((C))
node2((A))
node3((E))
node4((B))
node5((D))
node6((F))
node7((G))
node8((H))
node1---node2
node1---node3
node2---node4
node4---node7
node7---node8
node3---node5
node3---node6
其后序遍历为HGBADFEC
搜索
1 | template<typename T> |
最坏情况下,树转换为链表,时间复杂度为$O(n)$,一般情况下为$O(\text{lg}n)$。
判断是否平衡
LeetCode110:给定一个二叉树,判断它是否是高度平衡的二叉树。本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
注意,要保证每个节点左右子树高度差绝对值均不超过1
1 | // 计算树高 |
二叉树相关技巧
使用哑节点避免边界讨论
和链表处理方式类似,对于二叉树,我们同样可以使用哑节点的方式,回避掉一些边界讨论,例如897. 递增顺序查找树
给你一个树,请你 按中序遍历 重新排列树,使树中最左边的结点现在是树的根,并且每个结点没有左子结点,只有一个右子结点。
特殊二叉树
堆(优先队列)
堆是一种特殊的树状结构,堆又被称为优先队列(实际并不是队列),堆实际上划分出了元素的优先级,堆的实例很常见,例如:商务舱的旅客先上车、一等座的旅客次之、二等座最后,另一个例子是linux中的调度器,高优先级的进程优先执行、低优先级的会等待。
堆的实现
堆的经典实现是利用完全二叉树,为了实现堆操作,需要额外规定:任意节点优先级不小于其子节点,若母节点的值恒小于等于子节点的值,此堆称为最小堆(min heap);反之,若母节点的值恒大于等于子节点的值,此堆称为最大堆(max heap)。在堆中最顶端的那一个节点,称作根节点(root node),根节点本身没有母节点(parent node)。
堆的应用
堆的一个经典应用是堆排序,例题如LeetCode 215,在未排序的数组中找到第 k 个最大的元素。朴素的算法是先排序再输出第k个最大元素,这样的复杂度不是很理想,我们可以维护一个大小始终为k的最小堆,遍历整个数组,当遍历完成后,数组顶端的元素就是第 k 个最大的元素。
1 | class Solution { |
完全二叉树
完全二叉树定义
在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
完全二叉树节点数目计算
假设树的高度为$d$,那么第0层有$2^0=1$个节点,第$k$层有$2^{k}$个节点,除了最后一层以外的所有节点数为:$\sum_{k=0}^{k=d-1}2^k=2^d-1$,所以完全二叉树的节点数目计算问题可以退化为计算树高以及最后一层的节点数目,我们可以使用二分搜索的方式计算最后一层节点数目。同时,由于完全二叉树的定义,其树高的计算可以简化,一直循环直到左子数为空,即可计算得到树高。
1 | class Solution { |
二叉搜索树
二叉搜索树的特性
- 节点的左子树只包含小于当前节点的数;节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
空树是二叉搜索树
一个二叉搜索树的前序遍历一定是局部递减,整体递增的,利用这个性质我们可以判断一个数列是否为二叉搜索树前序遍历。局部递减是指左子数可能是递减的,而整体递增是因为右子树节点值大于左子树节点值,因此按照先访问左子树再访问右子树的顺序,得到的一定是整体递增的
255. 验证前序遍历序列二叉搜索树
给定一个整数数组,你需要验证它是否是一个二叉搜索树正确的先序遍历序列。你可以假定该序列中的数都是不相同的。例如:
1 | 5 |
- 一个二叉搜索树的中序遍历可以获得升序或降序的数组
二叉搜索树常见操作
二叉搜索树的中序遍历
二叉搜索树由于其特殊性质,中序遍历的结果为一个单调数组,根据这一特性,我们在解决二叉搜索树问题时,可以优先考虑中序遍历。中序遍历有两种,分别为左中右和右中左,对应的数组分别为递增和递减。
例题
给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和。
思路
当我们以右中左的顺序遍历二叉树时,可以得到单调递减的数列,那么我们只要求这个数列的前缀和,即可将树改造为题目的要求
验证是否为二叉搜索树(LeetCode98)
给定二叉树,判断是否为二叉搜索树
1 | //这个问题中的一个难点是,当前的树和左右子树都必须为二叉搜索树 |
二叉搜索树中的索引
由于二叉搜索树的特性,在二叉搜索树中索引某一个值,一定会出现三种情况:
- 如果
root->val == target,返回 - 如果
root->val < target,那么我们需要到root的右子树中寻找 - 如果
root->val > target,那么我们需要到root的左子树中寻找
例题1 二叉搜索树中的顺序后继
给你一个二叉搜索树和其中的某一个结点,请你找出该结点在树中顺序后继的节点。结点
p的后继是值比p.val大的结点中键值最小的结点。
思路:
这个题的一般思路是中序遍历二叉树得到递增序列然后找到后继结点,但是这样没有充分利用二叉搜索树的特性,我们可以按照索引的三种情况,搜索后继结点,代码如下:
1 | TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) { |
二叉搜索树相关例题
二叉树数据结构TreeNode可用来表示单向链表(其中left置空,right为下一个链表节点)。实现一个方法,把二叉搜索树转换为单向链表,要求值的顺序保持不变,转换操作应是原址的,也就是在原始的二叉搜索树上直接修改。
返回转换后的单向链表的头节点。
输入: [4,2,5,1,3,null,6,0]
输出: [0,null,1,null,2,null,3,null,4,null,5,null,6]
思路
看到升序序列,一定是二叉搜索树的中序遍历,故我们先写好中序遍历的框架,然后考虑如何对树进行修改。假设我们当前访问的树节点为curr,那么我们首先要做的操作是将该节点左子树置空,然后将该节点拼接至前一个节点的右子树上,所以我们需要一个节点prev记录中序遍历过程中的前一个节点。同时,为了处理链表起始的情况,我们定义一个哑节点head,一开始prev=head,最后返回head->next
graph TB
node1((4))
node2((2))
node3((5))
node4((1))
node5((3))
node6((null))
node7((6))
node8((0))
node1-->node2
node1-->node3
node2-->node4
node2-->node5
node3-->node6
node3-->node7
node4-->node8
如上图所示,经过前序便利,curr分别为0,1,2,3,4,5,6,而prev为head,0,1,2,3,4,5,算法如下:
1 | //中序遍历过程中 |
代码
使用遍历进行修改的代码如下:
1 | class Solution { |
使用递归进行修改代码如下:
1 | public TreeNode convertBiNode(TreeNode root) { |
二叉搜索树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。
思路
通过中序遍历我们能够找到两个错误的节点,然后只要交换两节点即可,这里需要注意的是,当我们找到了cur和pre,使cur->val < pre->val时,我们需要确定到底是cur是错误节点还是pre是错误节点。通过举例可知,第一次遇到错误的排序时,pre是错误的节点,而第二次遇到时,cur是错误的节点
1 | //中序遍历如下,其中2和4位置发生了交换 |
代码
1 | if(pre != nullptr){ |
AVL树
AVL树是一种可以进行局部平衡的树,它要求每个节点左右子树高度差最大为1。其高度受限于$O(lgn)$,平均查找次数接近于最好情况。
平衡条件
当AVL树中任意节点平衡因子绝对值大于1,树就需要平衡。
平衡过程
平衡的过程可以用
红黑树
红黑树是一种自平衡二叉查找树,典型用途是实现关联容器例如set或map的底层实现。推荐一个网站,可以可视化红黑树:红黑树可视化
性质
- 节点要么红要么黑
- 根黑叶黑红子黑(红节点子节点为黑节点)
- 任意节点到每个叶子节点包含相同数目的黑色节点
- 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长,因此树是大致平衡的
平衡过程
左旋
将某个node的右子树逆时针旋转,使得右子树的根节点成为node的父节点,并调整相关节点引用
右旋
将某个node的左子树顺时针旋转,使得左子树的根节点成为node的父节点,并调整相关节点引用
线段树
线段树能够把对区间的修改、维护从O(N)时间复杂度降低为对数复杂度
Leetcode上关于树的相关题目
493. 翻转对
给定一个数组nums,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个重要翻转对。返回给定数组中的重要翻转对的数量。
1 | 输入: [1,3,2,3,1] |
解析:
- 暴力搜索就不说了,这里给出使用二叉搜索树的解决方案:
- 树节点
1 | class Node{ |
- 插入
1 | Node* insert(Node *head, int val){ |
- 搜索
1 | int search(Node* head, long long target){ |
- 解决问题
1 | class Solution { |
二叉搜索树在最坏情况下的时间复杂度是$O(n^2)$。
- 使用二进制索引树进行处理
使用BST时,如果树不平衡,那么搜索效率会下降,因此可以采用红黑树或AVL树进行平衡,但是写起来太麻烦了,这里可以采用BIT,即树状数组进行处理,使时间复杂度为$ O(nlogn)$。树状数组的一个典型应用场合为计算子数组的和
114 利用二叉树的右节点将二叉树展开为链表
给定一个二叉树,原地将它展开为链表。例如,给定二叉树
1 | 1 |
将其展开为:
1 | 1 |
- 解法1,先序遍历直接嫁接:
- 将原来的右子树接到左子树的最右边节点
- 将左子树插入到右子树的地方
- 考虑新的右子树的根节点,一直重复上边的过程,直到新的右子树为 null
以上思路可以用图表示为:
1 | 1 |
解法1代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void flatten(TreeNode* root) {
TreeNode* p = root;
while(p != nullptr){
if(p->left == nullptr){ //左节点为空,直接考虑下一个节点
p = p->right;
}
else{
TreeNode* left = p->left;
while(left->right != nullptr) left = left->right; //找到左子树的右子节点
left->right = p->right; //将右子树嫁接到左子树的右子节点
p->right = p->left; //左子树转移到右子树
p->left = nullptr; //清空左子树
p=p->right; //考虑下一个节点
}
}
}
- 解法2:后序遍历逆序更新
366. 寻找二叉树的叶子节点
给你一棵二叉树,请按以下要求的顺序收集它的全部节点:
- 依次从左到右,每次收集并删除所有的叶子节点
- 重复如上过程直到整棵树为空
1 | 输入: [1,2,3,4,5] |
思路
边界值及返回条件确定
- 当树为空时,直接返回空列表
- 当树不为空时,需要进行操作,找到所有的叶子节点,并分组保存
搜索空间确定
大搜索空间
每次搜索会删去树的所有叶子节点,然后对删去叶子节点的树进行搜索,搜索空间为每次去掉叶子的树的集合,时间复杂度为O(H),即树的最大深度。
graph TB
node1((1))
node2((2))
node3((3))
node4((4))
node5((5))
node6((6))
node1---node2
node1---node3
node2---node4
node2---node5
node4---node6
node11((1))
node22((2))
node44((4))
node11---node22
node22---node44
node111((1))
node222((2))
node111---node222
node((1))
小搜索空间
小搜索空间为每棵树的每一个节点,即遍历一棵树的复杂度
搜索过程
搜索过程分为两步
- 遍历所有可能的树
- 在每一种可能的树中遍历所有节点
在每一种可能的树中遍历所有节点
我们先解决第二个问题:一个朴素的想法是每次循环删除所有的叶节点,重复若干次。这意味着我们要保存叶子节点(cur)的父节点(pre),当找到叶子节点后进行判断,如果pre->left == cur,那么令pre->left == nullptr;否则令pre->right == nullptr。
- 找到叶子节点
- 保存叶子节点的值
- 删除叶子节点
- 对左右子树执行相同的操作
1 | //一次操作的过程 |
遍历所有可能的树
在此过程中,我们不断地遍历以root作为跟节点的树,并每次进行剪去叶片的处理,直到只剩下一个单独的根为止,每次遍历我们需要记录下当前的所有叶子节点,然后在遍历完成后将结果数组保存。
1 | vector<vector<int>> findLeaves(TreeNode* root) { |