Listen, a tree is growing
有两个以上节点的树叫做多叉树。
B树家族
B树的典型应用是磁盘信息的存储,如果采用二叉树,会导致存储的信息过于分散,从而增大读取时间。
B树
B树操作
查找操作
插入操作
在插入过程中,会遇到三种情况:
- 键值放入有空间的叶节点中
这种情况直接把值放进去就可以。
- 要插入键值的叶节点已经满了
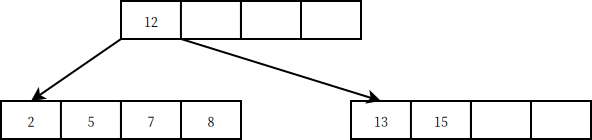
第一步,分裂叶节点,创建一个新叶节点,然后将已经慢了的一半键值转移至新叶节点中

第二步,将中间值放入父节点中,然后在父节点中放置一个指向新节点的指针,这里的中间值为6

- 一种特殊情况,B树的根节点满了,这是唯一一个会引起B树高度增长的情况

- 删除操作
- 如果删除键值K后,叶节点保持半满,那么直接删除即可
- 如果不能保持半满,会引起下溢
B*树
B*树是B树的一种变种,要求除了根节点至少$2/3$满
B+树
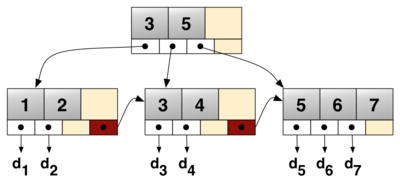
什么是B+树
B+树可以简单理解为:叶节点是数据,内部节点是索引集。
- 内部节点:存储键值、键值数量及指针
- 叶节点:存储键值、数据文件中与键值对应的引用以及指向下一叶节点的指针
B+树的技术特点与约束
- 阶数$m$,每个节点中最多键值数,即上图一个大节点中的键值个数
- 半满约束,内节点键值最少为$\left \lfloor \frac{m}{2}+1 \right \rfloor$,即半满状态,当然根节点除外,根节点可以只有一个键值
- 每个节点对应一页的大小
B+树操作
- 搜索算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14func tree-search(nodePointer, search-key-value K) return nodePointer
if *nodePointer 是叶节点 then
return nodePointer;
else
if K<K1 then
return tree_search(P[0],K);
else if K >= Kn then
return tree_search(P[n],K);
else
find i such that Ki<=K<=Ki+1
return tree_search(Pi,K);
endif
endif
endfunc;
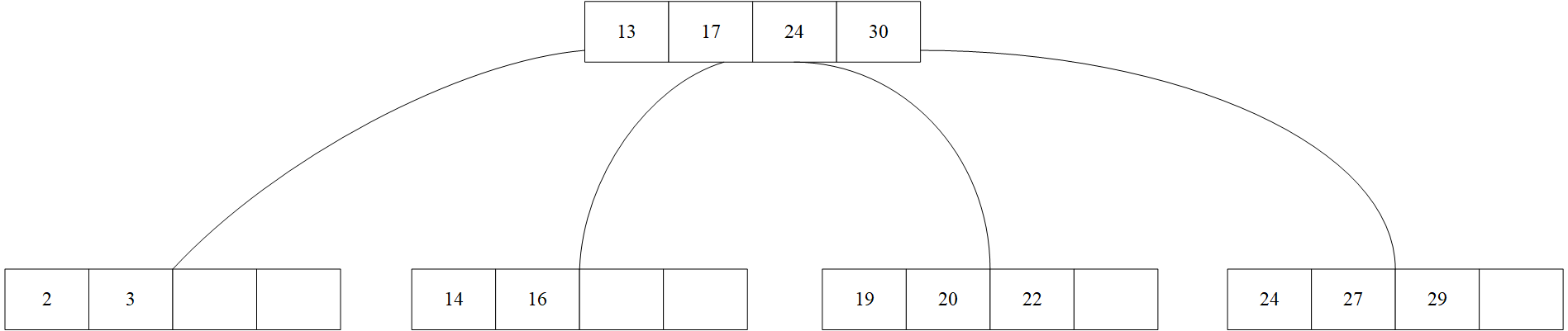
从上面的图可知,节点中的值是进行排序的,且小于父节点中的值。
- 插入算法(节点分裂)
以上图为例,插入18,可以发现节点未满,直接将18放入节点即可
插入8,发现需要被插入的节点已经满了,因此需要创建一个新的节点,来放置新的值,同时由于第一个节点已经满了,因此将节点1中的一半的值放进新节点中。
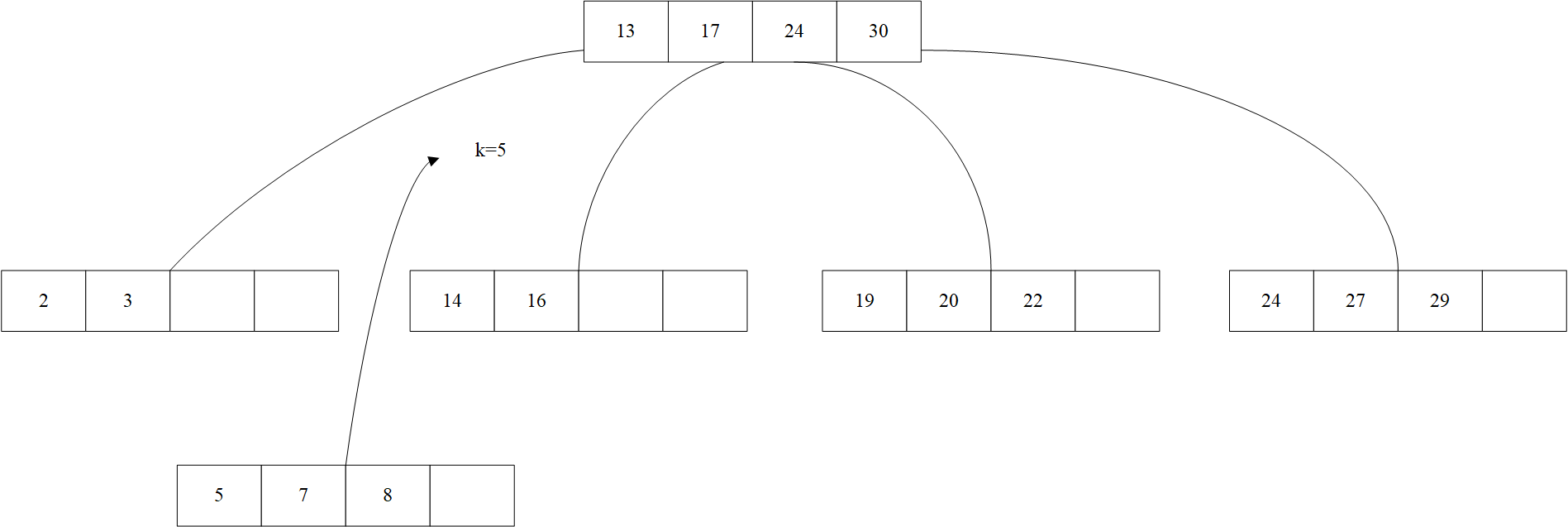
然后多了一个节点需要处理,有一个指针引向了上层,然而发现根节点已经没有位置了,就需要对根节点进行分裂,提出中间值作为根节点,然后将剩下的值进行分裂。
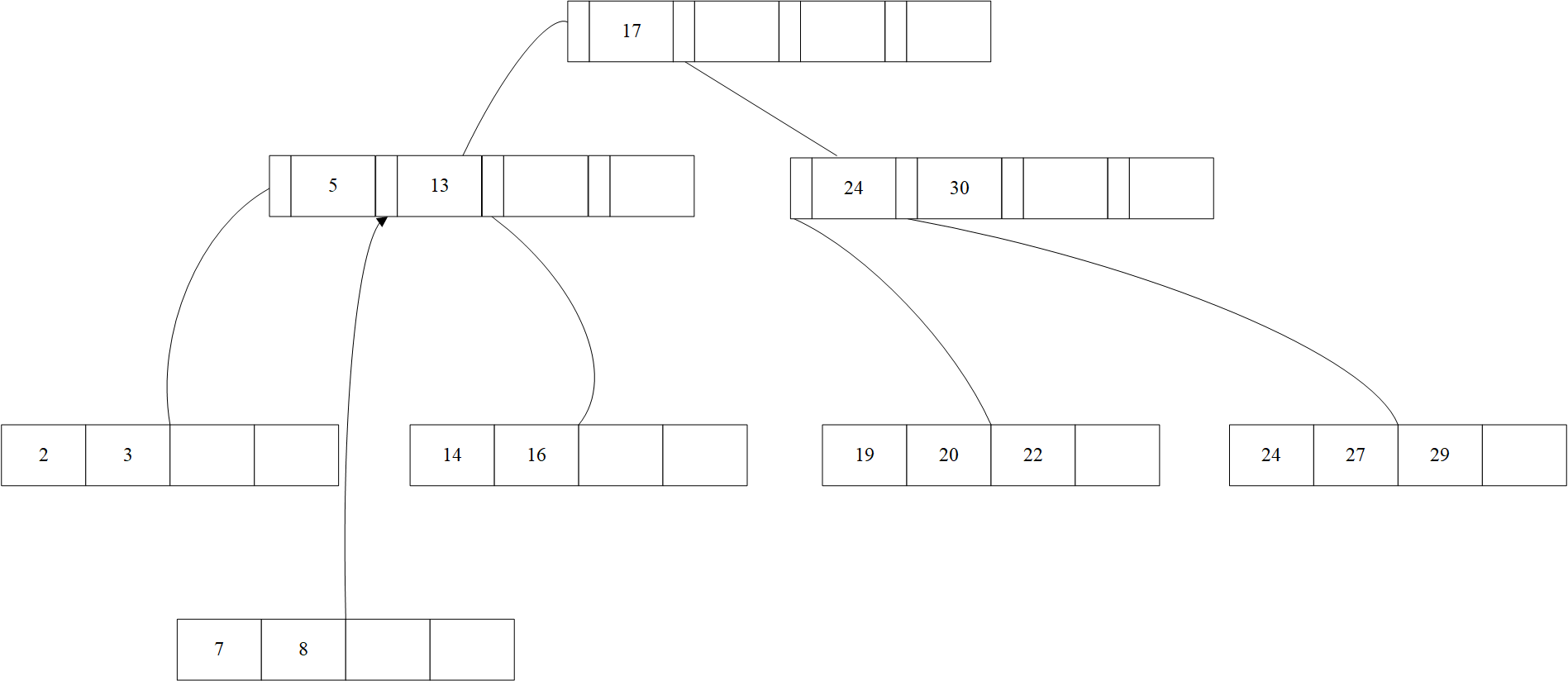
可以看到树深度增加了。B+树的插入算法如下所示:
1 | // C++ program for B-Tree insertion |
删除算法(节点合并)
B与B+树的区别
B+树是B树的延伸,他们的主要区别如下
| B Tree | B+ Tree |
|---|---|
| 数据存放在叶节点和普通节点中 | 数据只存放在叶节点中 |
| 搜索速度较慢 | 搜索速度较快 |
| 不需要额外的索引键 | 需要保存额外的索引键 |
| 删除操作很复杂 | 删除操作比较简单,因为数据可以直接从叶节点中删除 |
| 叶节点相互之间没有连接 | 叶节点通过链表方式进行连接,从而便于遍历操作 |
字典树(前缀树)
字典树的定义
Trie树,即字典树,又称单词查找树或键树,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。字典树的基本原理就像查询字典一样,因此可以快速定位单词,非常高效。
字典树的性质
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
字典树及其方法的实现
下面给出一种常用字典树及其方法的实现,包括添加单词和搜索单词两种操作,字典树类成员变量如下:
1 | private: |
一些基本成员函数如下所示:
1 | Trie() : children{vector<Trie*>(R)}, |
插入键
我们通过搜索 Trie 树来插入一个键。我们从根开始搜索它对应于第一个键字符的链接。有两种情况:
- 链接存在。沿着链接移动到树的下一个子层。算法继续搜索下一个键字符。
- 链接不存在。创建一个新的节点,并将它与父节点的链接相连,该链接与当前的键字符相匹配。
重复以上步骤,直到到达键的最后一个字符,然后将当前节点标记为结束节点,算法完成。
1 | void insert(string word) { |
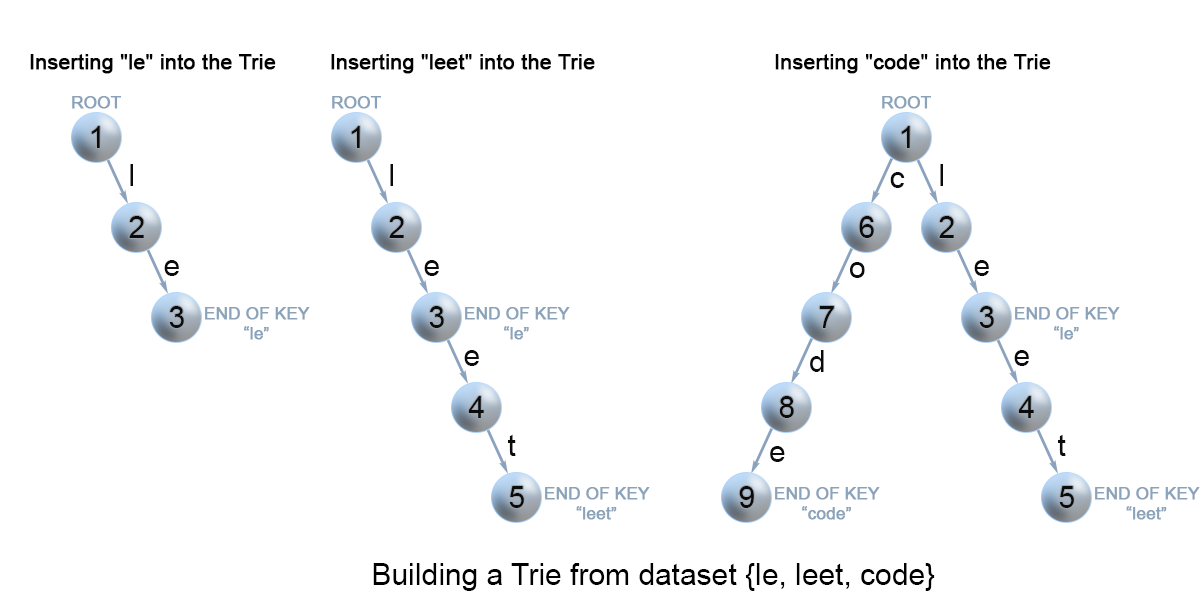
搜索键及前缀
每个键在 trie 中表示为从根到内部节点或叶的路径。我们用第一个键字符从根开始,。检查当前节点中与键字符对应的链接。有两种情况:
存在链接。我们移动到该链接后面路径中的下一个节点,并继续搜索下一个键字符。
不存在链接。若已无键字符,且当前结点标记为 isEnd,则返回 true。否则有两种可能,均返回 false :
- 还有键字符剩余,但无法跟随 Trie 树的键路径,找不到键。
- 没有键字符剩余,但当前结点没有标记为 isEnd。也就是说,待查找键只是Trie树中另一个键的前缀。
1 | bool search(string word) { |
搜索前缀与搜索键类似,只是不需要判断是否结尾,如果前缀能够完整在树中找到,那么直接返回true即可:
1 | bool startsWith(string prefix) { |
字典树应用场景
字典树常用应用场景如下:
- 自动补全
- 拼写检查
- IP路由
- 打字预测等
字典树与哈希表对比
尽管哈希表可以在 $O(1)$ 时间内寻找键值,却无法高效的完成以下操作:
- 找到具有同一前缀的全部键值
- 按词典序枚举字符串的数据集
Trie 树优于哈希表的另一个理由是,随着哈希表大小增加,会出现大量的冲突,时间复杂度可能增加到$O(n)$,其中 $n$ 是插入的键的数量。与哈希表相比,Trie 树在存储多个具有相同前缀的键时可以使用较少的空间。此时 Trie 树只需要 $O(m)$ 的时间复杂度,其中$m$为键长。而在平衡树中查找键值需要$O(m \log n)$ 时间复杂度。