一去二三里,烟村四五家,亭台六七座,八九十枝花
基本排序算法
插入排序(稳定)
原理
将数组分为未排序的和已排序的两部分,在未排序的数组中依次读取新的元素,然后在已经排好序的数组中进行插入操作。关于插入排序更详细的描述请参考MIT课程中关于sort排序的讲解
性能
- 优点:已经排列好的数据不会被移动
- 缺点:插入动作可能导致大量元素的移动,平均时间复杂度为$O(n^2)$
实现
1 | template <typename T> |
- 何时使用:当不需要额外空间,排序比较简单,当对连续的数据流进行排序时
- 何时不用:当平均情况很差时
选择排序(不稳定)
原理
找到数组中最小的元素,将其与第一个位置的元素交换,然后在剩余的data[1],……,data[n]中找到最小的元素,把他放到第二个位置。
性能
- 优点:赋值次数少
- 缺点:交换次数多
实现
1 | template<typename T> |
冒泡排序(稳定)
原理
不断交换相邻逆序元素实现排序
性能
- 优点:空间复杂度为$O(1)$
- 缺点:时间复杂度$O(n^2)$,做了大量无用比较
实现
1 | template<typename T> |
高效排序算法
希尔排序(不稳定)
原理
实际上是一种改进的插入排序算法,将数组分为$h$个子数组,然后每一段进行排序,排序方法一般选择插入排序(考虑插入排序的优点,对几乎已经排好的数据可以达到线性操作)。
增量选择一般服从如下条件:
当$h_{i+1}>n$时停止,希尔排序的原理可以用如下图进行表示:
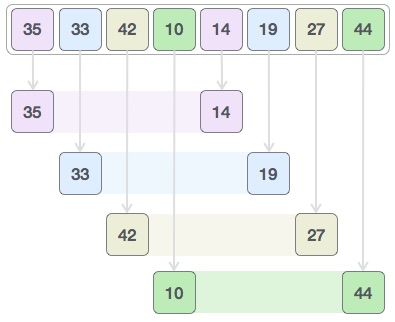
此处$h=4$,先对跨步长选取的子数组进行排序,排好序之后数列变为14 19 27 10 35 33 27 44,然后令$h=1$,再进行选择排序即可
性能
- 优点:降低了时间复杂度
- 缺点:不稳定,复杂度仍然较高
实现
1 | template<typename T> |
堆排序(不稳定)
原理
利用堆这种数据结构所设计的一种排序算法,堆本身是一个完全二叉树
性能
实现
1 | void heapify(int arr[], int n, int i) //创建堆,将堆的末端子节点作调整,使得子节点永远小于父节点 |
快速排序(不稳定)
原理
在排序时设置基准点,将小于基准点的数放置在左侧,大于的则放置在右侧,交换距离增大。快速排序本质上是一种基于二分法的递归排序方法,同时,快速排序还利用到了双指针。快速排序是不稳定的。
性能
- 优点:平均时间复杂度低($O(NlogN)$)
- 缺点:如果数组中最小(大)的元素被选为边界点,那么时间复杂度为$O(n^2)$,不适合小数组
快速排序步骤:
- 找到边界值(通常以数组中间值作为边界值)
- 扫描数组,将数组中元素放入适当的子数组中
1 | template<class T> |
为了解决上述代码中的问题(如果数组中最小(大)的元素被选为边界点),可以加入一段辅助代码
1 | void quicksort(vector<int>& nums, int n){ |
常见应用
快速排序的思想在很多场合都可以借鉴,特别是在涉及数组元素移动的问题中。
一 LeetCode 283. 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
思路
我们可以设置快慢指针,慢指针指向0,快指针指向0后的第一个非0元素,然后交换快慢指针所指的值,然后递增慢指针。这里某个元素是否为0就可以视作快速排序中的基准值,代码如下:
1 | void moveZeroes(vector<int>& nums) { |
归并排序
原理
分而治之,对子数组进行排序,分治的思想也可以延续到许多问题中。
性能
- 优点:最好和最坏情况下时间复杂度相同,都是$O(n\text{log}n)$
- 缺点:合并数组需要额外空间
实现
1 | // Merges two subarrays of arr[]. |
归并排序原理上并不难理解,难的是如何实现相关代码,这里利用了递归的方式,空间复杂度是$O(n)$,如果想使空间复杂度为常数,可以使用自底向上的归并算法。
自底向上的归并算法,先两两排序合并,在44排序合并,直至结束,例如:[4,3,1,7,8,9,2,11,5,6],其合并过程为1:
1 | step=1: (3->4)->(1->7)->(8->9)->(2->11)->(5->6) |
实现:
见链表章节,使用归并排序对链表进行操作。
基数排序
单词的排序实际上就是基数排序,每一个字母表中包含了开头是相同字母的单词,然后再根据第二个字母,第三个字母这样依次划分下去。
实现
1 |
计数排序
原理
通过对数组中每个数字i出现的次数进行计数,将个数添加至count[i]中。
性能
- 优点:线性排序
- 缺点:如果数据偏差很大,可能导致空间开销非常大
自定义排序
在有些情况下,排序规则可能比较复杂,此时我们需要自定义排序规则,此处举一些例子总结自定义排序的写法。
字典序
31. 下一个排列
实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须原地修改,只允许使用额外常数空间。
以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
C++ STL中有关于字典序排列的函数,用法如下:next_permutation(nums.begin(), nums.end());
排序算法复杂度分析
排序算法本质上可以转换一个决策树问题,根据决策树的深度可知,排序算法平均情况下最好的时间复杂度为$O(NlogN)$