Life is short, always choose the best
In this article, we are going to give a summarization about the LQG regulator. Like the pole placement control law, the LQG can also guide us to determine the parameters in a full state-feedback controller.
Prerequisite knowledge
Linear quadratic regulator
Before talking about the LQG regulator, let’s first discuss about LQR since it is a simplified form about LQG. (without Gaussian noises)
A simple problem
Consider you are going to a park (desired state) from your home (initial state), you have several choices:
| Time | Cost | |
|---|---|---|
| Car | 20min | 7 |
| Bike | 75min | 0 |
| Bus | 30min | 2 |
| Airplane | 4min | 400 |
If you want speed, choose airplane, if you have little money, choose bike, or you can make a compromise between time and money to take a car or a bus.
Define a cost function:
where $t$ is time and $m$ is money, $Q$ and $R$ are two weight matrix. Based on the cost function, we make the optimal choose. Remember that the cost is strongly related to the weight matrix.
LQR in control system
Now let’s consider our control system, we want to make a balance between the performance and actuator effort (energy). So we set up a cost function of the performance ($x$) and the effort ($u$):
by solving the LQR problem, it returns the gain matrix $K$ that produce the lowest cost given the dynamic system. We penalizing the performance by $Q$ and penalizing the effort by $R$. Thus the function of LQR is:
Given a system function with initial state, by providing a proper control quantity, the system can be transfered to a desired terminal state with lowest cost.
Intuitive understand of the cost in system
Performance is judged by the state $x$. Suppose that our system is at a none zero initial state, we want it to get to the zero state. The faster it return to zero, the better the performance is and the lower the cost. How to measure how quickly to return the desired state is to looking at the area under the curve, this is what the integral doing, a curve with less area means a better performance. Since the state can be either positive and negative, we square the value to keep positive.
The operation above turns our cost function to a quadratic function with a form of $z=x^2+y^2$, it has a definite minimum value (Great!). Now let’s consider the form of $Q$, the $Q$ needs to be positive definite thus $x^{\top} Q x>0$, normally it is a diagonal matrix:
Similarly, the $R$ matrix can penalize the input $u$, we can rewrite the equation as follows:
Now we can make a judgment, for example, if an actuator $u_i$ is really expensive, we can penalizing it by increasing $r_i$, if lower error $x_i$ is important, you can increasing the $q_i$.
Mathematical form and solution about LQR
For a continuous-time linear system, defined on $t \in\left[t{0}, t{1}\right]$, described by:
with a quadratic cost function defined as:
in which:
- $x^{\top}\left(t{1}\right) F\left(t{1}\right) x\left(t_{1}\right)$ is an index about steady state
- $\int{t{0}}^{t_{1}}x^{\top} Q x d t$ is an index about transient process
- $\int{t{0}}^{t_{1}}u^{\top} R u d t$ is an index about system energy
The feedback control law that minimizes the value of the cost is:
Solution: Now let’s solve the LQR problem, taking discrete LQR as an example, we use Lagrangian multiplier method to solve it, given the optimization problem:
Step1: Create Lagrangian function to combine the cost function and constrains.
Using the Lagrangian multiplier $\lambda$, we can create a function combine the cost function and constrains.
where
Step2: Find the extreme point we of the cost function
finding the minimum of $J_l$ is to find the extreme point of $J_l$, thus we need to satisfy the following conditions:
meanwhile, the final state satisfies:
Step3: Solving the control law and feedback gain
With a series transformation and solving a Riccati function, we get the control law
and feedback gain
That is the feedback regulator we need.
In Matlab, give $Q$ and $R$, run
1 | K = lqr(A,B,Q,R) |
you get the optimal gain set. With LQR, we don’t place poles, instead, we choose $Q$ and $R$, now here’s the question, what is a proper $Q$ and $R$, it can based on our intuition and knowledge about the system, Or we can start with $Q$ and $R$ equals to identity matrix. Here we summarize the influence of $Q$ and $R$ to the system.
| Overshoot | Setting time | Energy consumption | |
|---|---|---|---|
| Increasing $Q$ | decreasing | decreasing | increasing |
| Increasing $R$ | increasing | increasing | decreasing |
Difference of LQR and pole placement
Basically, the LQR and pole placement controllers have the exactly the same structure, so the implementation of $K$ is the same, but how we choose $K$ is different.
- In pole placement, we solve for $K$ by choosing pole locations.
- In LQR, we find the optimal $K$ by choosing characteristics.
Linear quadratic estimator
Filtering, Prediction, and Smoothing3
There are three general types of estimators for the LQG problem:
- Predictors: use prior observations strictly $t{obs}<t{est}$
- Filter: use observations up to and including the time that the state of the dynamic system is to be estimated $t{obs}\leq t{est}$
- Smoother: use observations beyond the estimation time $t{obs}>t{est}$
Kalman Filter
The Kalman filter is an optimal algorithm for state estimation, it will help us to reconstruct the state of a dynamic system uses a series measurements observed over time, containing statistical noise and other inaccuracies, and produces estimates of unknown variables that tend to be more accurate than those based on a single measurement alone. For more information about Kalman filter, please refer to Kalman filter for this section.
Linear quadratic Gaussian regulator
Mathematical description of the problem
Let’s concern a linear system driven by addictive white Gaussian noise ($N(0,\Sigma)$), consider a continuous-time linear dynamic system with disturbance and measurement noise:
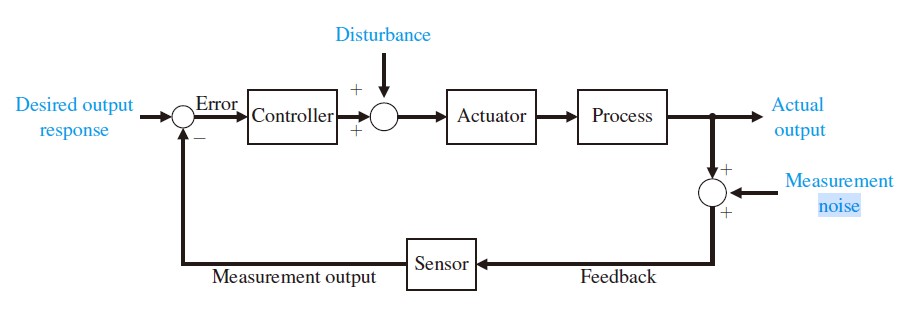
here the $\mathbf{v}(t)$ and $\mathbf{w}(t)$ are the system noise and measurement noise. The objective of LQG is to find the control input history $\mathbf{u}(t)$ which at any time only depends linearly on the past measurement $\mathbf{y}\left(t^{\prime}\right), 0 \leq t^{\prime}<t$ such that the following cost function is minimized:
where $\mathbb{E}$ denotes the expected value $T$ may be either finite or infinite, if infinite, the first term $\mathbf{x}^{\mathrm{T}}(T) F \mathbf{x}(T)$ can be ignored.
Here we gives out a simple explanation about why we regard the noise as Gaussian. A Gaussian noise means that if we added multiple noises, it will still obey the Gaussian distribution.
Regulator design
Now let’s design the LQG regulator, the LQG controller that solves the LQG control problem is specified by the following equations:
where matrix $L(t)$ is the gain of the state estimator (Kalman gain) while $K(t)$ is the feedback gain.
Solve for $L(t)$
$L(t)$ is computed from $A(t),C(t),V(t),W(t)$ and finally $\mathbb{E}\left[\mathbf{x}(0) \mathbf{x}^{\mathrm{T}}(0)\right]$ through the following associated matrix Riccati differential equation:
Given the solution $P(t), 0 \leq t \leq T$ the Kalman gain equals
Solve for $K(t)$
Similar to solving for $L(t)$, the feedback gain $K(t)$ can be determined by the following Riccati differential equation:
Given the solution $S(t), 0 \leq t \leq T$ the feedback gain equals
The Riccati differential equation of $L(t)$ solves the linear–quadratic estimation problem (LQE) while the second LQR problem, together they solve the linear-quadratic Gaussian control problem. So the LQG problem separates into the LQE and LQR problem that can be solved independently. Therefore, the LQG problem is called separable.
Application: LQG regulator design for a inverted pendulum system
In this section we will design a LQG regulator for a noise added inverted pendulum system which is basically an extended part of .